Entity Framework Core is a great ORM, that recently reached version 5. Is it fast? Is it faster than it’s predecessor, Entity Framework 6, which still offers slightly more functionality? Let’s check that out.
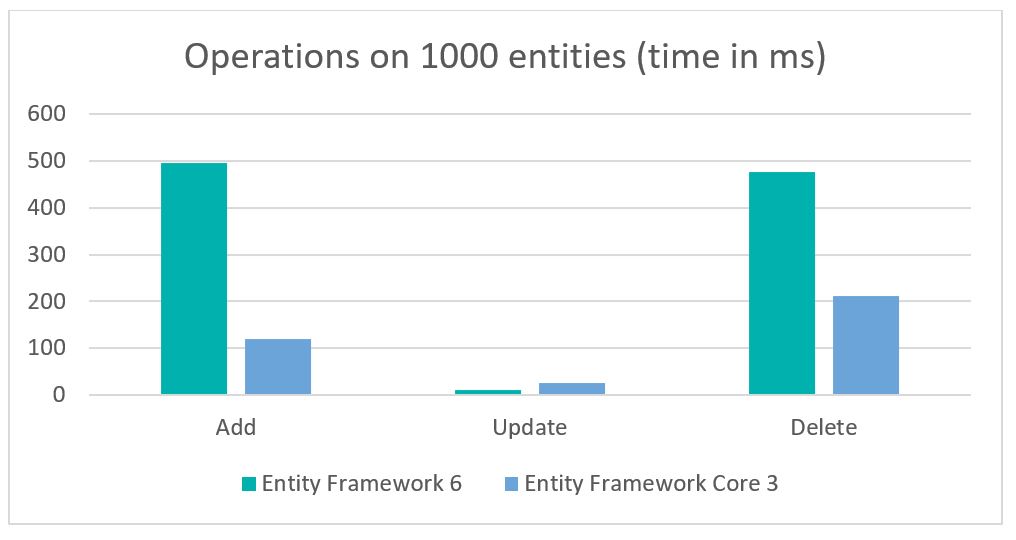
The conclusions are obvious: in almost every test conducted by Chad, Entity Framework Core 3 is faster than Entity Framework 6 – exactly 2.25 to 4.15 times faster! So if performance is important to your application and it operates on large amounts of data, EF Core should be a natural choice.
Is it faster than Dapper?
Dapper is a very popular object-relational mapper and, like EF Core, it facilitates working with the database. It’s called the king of Micro ORM because it’s very fast and does some of the work for us. If we compare EF Core and Dapper, we immediately notice that the capabilities of EF Core are much greater. Microsoft technology allows you to track objects, migrate the database schema, and interact with the database without writing SQL queries. Dapper, on the other hand, maps the objects returned by the database, but all SQL commands have to be written yourself. This certainly allows more freedom in operating the database, but there is a greater risk of making a mistake when writing a SQL query. Similarly to updating the database schema, EF Core can create changes and generate a migration by itself, and in Dapper, you have to manually edit the SQL code.
There is no doubt, however, that Dapper has its supporters, mainly due to its performance. On the blog exceptionnotfound.net we can find a comparison between Entity Framework Core 3 and Dapper version 2.
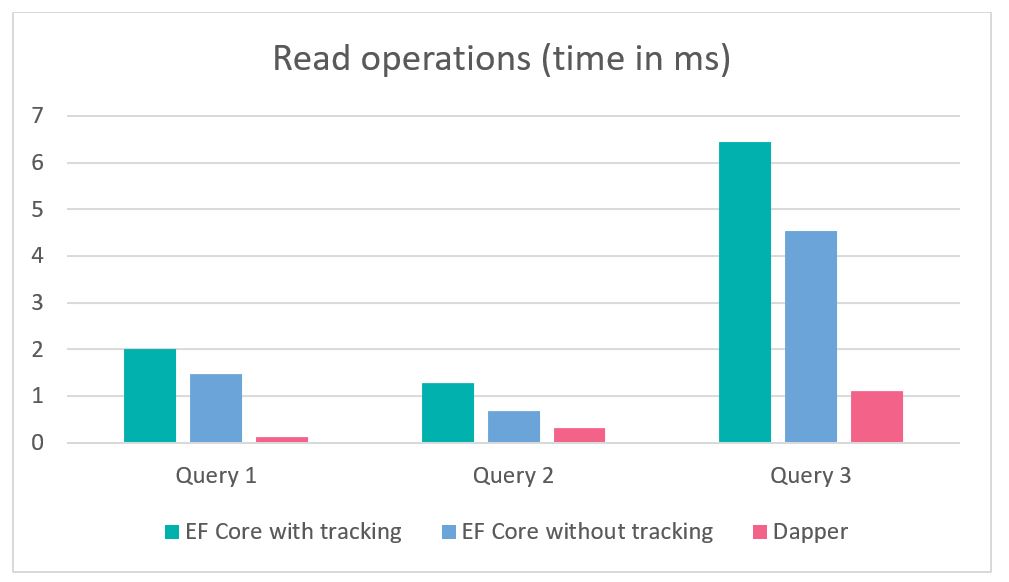
As you can see, we compare 3 database reads here, where Entity Framework Core with object tracking in one case, non-tracking in the other, and Dapper’s third. Tracking changes to entities in EF Core can be turned off with the AsNoTracking() option, which makes reading operations significantly faster. More information on this test can be found here: https://exceptionnotfound.net/dapper-vs-entity-framework-core-query-performance-benchmarking-2019/
Summary
All in all – Dapper is much faster to read from the database and will certainly be comparatively fast when writing. However, it requires writing SQL queries, which can expose the developer to errors. I have personally used Dapper on several projects, and basically, only one has been dictated by performance. For the simple logic of saving and retrieving data from the database, I would use Entity Framework Core because of its simplicity and convenience in introducing changes.
Entity Framework Core 5 is a great ORM to use and connect to the database with. It is easy to use and easy to understand. It offers just enough for the most common scenarios. So what about inserting big amounts of data in a one go? Would it be fast enough?
Let’s have a look at the code
As my example, I’ll take a very simple entity – a Profile and PrimeHotel repository available here at my GitHub.
My DbContext is very simple and it looks like this:
public class PrimeDbContext : DbContext
{
public PrimeDbContext(DbContextOptions<PrimeDbContext> options)
: base(options)
{
}
public virtual DbSet<Room> Rooms { get; set; }
public virtual DbSet<Profile> Profiles { get; set; }
public virtual DbSet<Reservation> Reservations { get; set; }
}
And Profile entity looks like this:
public class Profile
{
public int Id { get; set; }
public string Ref { get; set; }
public string Forename { get; set; }
public string Surname { get; set; }
public string TelNo { get; set; }
public string Email { get; set; }
public DateTime? DateOfBirth { get; set; }
}
Because I’ll be using WebApi for the ease of demonstration, I’ll create a ProfileController.
[ApiController]
[Route("[controller]")]
public class ProfileController : ControllerBase
{
private readonly PrimeDbContext primeDbContext;
private readonly string connectionString;
public ProfileController(PrimeDbContext _primeDbContext, IConfiguration _configuration)
{
connectionString = _configuration.GetConnectionString("HotelDB");
primeDbContext = _primeDbContext;
}
}
For now, it’s pretty empty, but now you get the base that we will start with.
Let’s get profiles… lots of them!
To test an insert of many entities at once we need to generate a lot of testing data. I like to have my test data as close to real values as possible, so to get those, I’ll use a Bogus nugget package.
Bogus is robust and very easy to use fake data generator. It will generate random values, that will fit a given context, like a surname, age, address, e-mail, company name, and so on. There are dozens of options. Go see for yourself in its documentation.
Generating any number of profiles will look like this:
private IEnumerable<Profile> GenerateProfiles(int count)
{
var profileGenerator = new Faker<Profile>()
.RuleFor(p => p.Ref, v => v.Person.UserName)
.RuleFor(p => p.Forename, v => v.Person.FirstName)
.RuleFor(p => p.Surname, v => v.Person.LastName)
.RuleFor(p => p.Email, v => v.Person.Email)
.RuleFor(p => p.TelNo, v => v.Person.Phone)
.RuleFor(p => p.DateOfBirth, v => v.Person.DateOfBirth);
return profileGenerator.Generate(count);
}
Inserting profiles with Entity Framework Core 5
I don’t want to send all those profiles in a request, because that would be a huge amount of data. Transferring that to a controller and deserialization on the ASP.NET Core 5 side can take a while, and it’s not really the part I want to test. This is why I choose to generate my profiles in the controller method and insert it right after that.
The code for the whole thing is really straightforward:
[HttpPost("GenerateAndInsert")]
public async Task<IActionResult> GenerateAndInsert([FromBody] int count = 1000)
{
Stopwatch s = new Stopwatch();
s.Start();
var profiles = GenerateProfiles(count);
var gererationTime = s.Elapsed.ToString();
s.Restart();
primeDbContext.Profiles.AddRange(profiles);
var insertedCount = await primeDbContext.SaveChangesAsync();
return Ok(new {
inserted = insertedCount,
generationTime = gererationTime,
insertTime = s.Elapsed.ToString()
});
}
Additionally, I added a Stopwatch to measure how long does it take to generate profiles as well as insert them. In the end, I’m returning an anonymous type to easily return more than one result at a time.
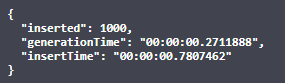
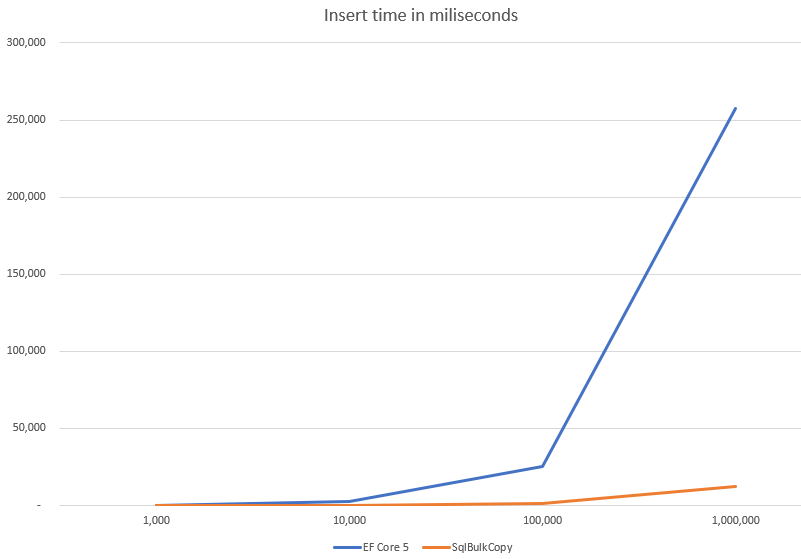
Finally, let’s test it out. For 1000 profiles I got:
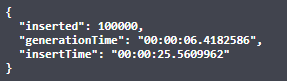
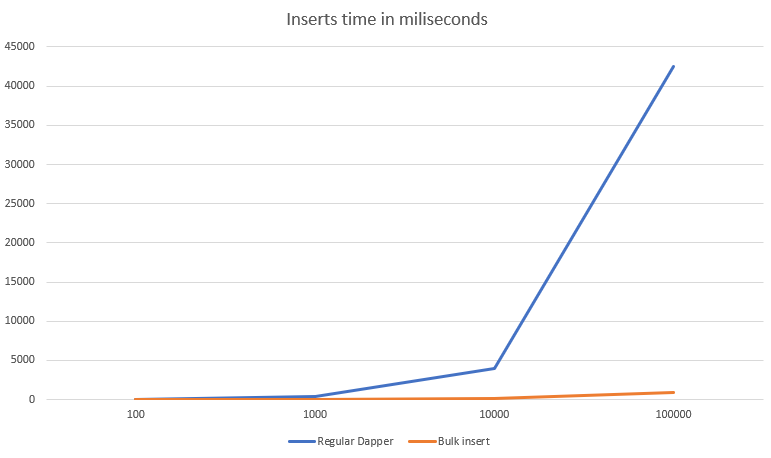
But wait, let’s try something bigger, like 100000 entities:
25 seconds? Really? Not that impressive.
What it does underneath? Let’s check with SQL Server Profiler:
exec sp_executesql N'SET NOCOUNT ON;
DECLARE @inserted0 TABLE ([Id] int, [_Position] [int]);
MERGE [Profiles] USING (
VALUES (@p0, @p1, @p2, @p3, @p4, @p5, @p6, 0),
(@p7, @p8, @p9, @p10, @p11, @p12, @p13, 1),
(@p14, @p15, @p16, @p17, @p18, @p19, @p20, 2),
(@p21, @p22, @p23, @p24, @p25, @p26, @p27, 3),
...
) AS i ([DateOfBirth], [Email], [Forename], [Ref], [ReservationId], [Surname], [TelNo], _Position) ON 1=0
WHEN NOT MATCHED THEN
INSERT ([DateOfBirth], [Email], [Forename], [Ref], [ReservationId], [Surname], [TelNo])
VALUES (i.[DateOfBirth], i.[Email], i.[Forename], i.[Ref], i.[ReservationId], i.[Surname], i.[TelNo])
OUTPUT INSERTED.[Id], i._Position
INTO @inserted0;
SELECT [t].[Id] FROM [Profiles] t
INNER JOIN @inserted0 i ON ([t].[Id] = [i].[Id])
ORDER BY [i].[_Position];
',N'@p0 datetime2(7),
@p1 nvarchar(4000),
@p2 nvarchar(4000),
@p3 nvarchar(4000),
@p4 int,
@p5 nvarchar(4000),
...
@p0='1995-02-22 09:40:44.0952799',
@p1=N'Sherri_Orn@gmail.com',
@p2=N'Sherri',
...
SqlBulkCopy to the rescue
SqlBulkCopy is a class that was introduced a while ago, specifically in .Net Framework 2.0 – 18 years ago! SqlBulkCopy will only work to save data in a SQL Server database, but its source can be anything, as long as it’s results can be loaded to DataTable or read by IDataReader.
Let’s have a look at how we can use it in our example.
[HttpPost("GenerateAndInsertWithSqlCopy")]
public async Task<IActionResult> GenerateAndInsertWithSqlCopy([FromBody] int count = 1000)
{
Stopwatch s = new Stopwatch();
s.Start();
var profiles = GenerateProfiles(count);
var gererationTime = s.Elapsed.ToString();
s.Restart();
var dt = new DataTable();
dt.Columns.Add("Id");
dt.Columns.Add("Ref");
dt.Columns.Add("Forename");
dt.Columns.Add("Surname");
dt.Columns.Add("Email");
dt.Columns.Add("TelNo");
dt.Columns.Add("DateOfBirth");
foreach (var profile in profiles)
{
dt.Rows.Add(string.Empty, profile.Ref, profile.Forename, profile.Surname, profile.Email, profile.TelNo, profile.DateOfBirth);
}
using var sqlBulk = new SqlBulkCopy(connectionString);
sqlBulk.DestinationTableName = "Profiles";
await sqlBulk.WriteToServerAsync(dt);
return Ok(new
{
inserted = dt.Rows.Count,
generationTime = gererationTime,
insertTime = s.Elapsed.ToString()
});
}
First, we need to define a DataTable. It needs to represent the Profiles table because this is our destination table that we are going to use.
Then with WriteToServerAsync we are loading profiles to the database. Let’s have a look at how does it looks like in SQL.
select @@trancount;
SET FMTONLY ON select * from [Profiles]
SET FMTONLY OFF exec ..sp_tablecollations_100 N'.[Profiles]'
insert bulk [Profiles] (
[Ref] NVarChar(max) COLLATE SQL_Latin1_General_CP1_CI_AS,
[Forename] NVarChar(max) COLLATE SQL_Latin1_General_CP1_CI_AS,
[Surname] NVarChar(max) COLLATE SQL_Latin1_General_CP1_CI_AS,
[TelNo] NVarChar(max) COLLATE SQL_Latin1_General_CP1_CI_AS,
[Email] NVarChar(max) COLLATE SQL_Latin1_General_CP1_CI_AS,
[DateOfBirth] DateTime2(7))
How does it work internally? StackOverflow comes with an answer:
SqlBulkCopy does not create a data file. It streams the data table directly from the .Net DataTable object to the server using the available communication protocol (Named Pipes, TCP/IP, etc…) and insert the data to the destination table in bulk using the same technique used by BCP.
Two totally different approaches. What about the performance? Let’s compare those two.
The performance
The outcome of a performance check is not a huge surprise. SqlBulkCopy is meant to insert data fast and it is extremely performant.
Big differences start to show when you insert more than 10 thousand entities at a time. Over that number, it might be wort to reimplement your code to use SqlBulkCopy instead of Entity Framework Core 5.
What about other operations?
When it comes to handling big amounts of data things are starting to be a little more tricky. You might want to take a look at the database improvements and what data you actually need to operate on. Have in mind that operations on big chunks of data are much faster when done on the database side.
I had a case once where I needed to perform and update on around a million entities, once a day. I combined a few things and it worked out pretty good.
create a temporary table, i.e. T1
insert data with SqlBulkCopy
perform an update on the database side
select any data you might need, i.e. for logging
delete a temporary table
I know this is moving business logic inside the database, but some sacrifices are required if this update operation needs to be fast.
Dapper is a simple object mapper, a nuget package that extends the IDbConnection interface. This powerful package come in handy when writing simple CRUD operations. The thing I struggle from time to time is handling big data with Dapper. When handling hundreds of thousands of objects at once brings a whole variety of performance problems you might run into. I’ll show you today how to handle many inserts with Dapper.
The problem
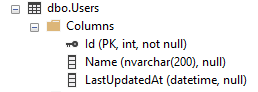
Let’s have a simple repository, that inserts users into DB. Table in DB will look like this:
Now let’s have a look at the code:
public async Task InsertMany(IEnumerable<string> userNames)
{
using (var connection = new SqlConnection(ConnectionString))
{
await connection.ExecuteAsync(
"INSERT INTO [Users] (Name, LastUpdatedAt) VALUES (@Name, getdate())",
userNames.Select(u => new { Name = u })).ConfigureAwait(false);
}
}
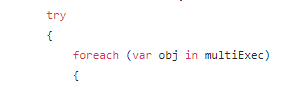
Very simple code, that takes user names and passes a collection of objects to Dapper extension method ExecuteAsync. This is a wonderful shortcut, that instead of one object, you can pass a collection and have this sql run for every object. No need to write a loop for that! But how this is done in Dapper? Lucky for us, Dapper code is open and available on GitHub. In SqlMapper.Async.cs on line 590 you will see:
There is a loop inside the code. Fine, nothing wrong with that… as long as you don’t need to work with big data. With this approach, you end up having a call to DB for every object in the list. We can do it better.
What if we could…
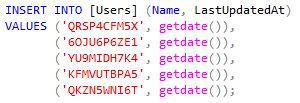
What if we could merge multiple insert sqls into one big sql? This brilliant idea gave me my colleague, Miron. Thanks, bro!:) So instead of having:
We can have:
The limit here is 1000, cause SQL server does not allow to set more values in one insert command. Code gets a bit more complicated, cause we need to create separate sqls for every 1000 users.
public async Task InsertInBulk(IList<string> userNames)
{
var sqls = GetSqlsInBatches(userNames);
using (var connection = new SqlConnection(ConnectionString))
{
foreach (var sql in sqls)
{
await connection.ExecuteAsync(sql);
}
}
}
private IList<string> GetSqlsInBatches(IList<string> userNames)
{
var insertSql = "INSERT INTO [Users] (Name, LastUpdatedAt) VALUES ";
var valuesSql = "('{0}', getdate())";
var batchSize = 1000;
var sqlsToExecute = new List<string>();
var numberOfBatches = (int)Math.Ceiling((double)userNames.Count / batchSize);
for (int i = 0; i < numberOfBatches; i++)
{
var userToInsert = userNames.Skip(i * batchSize).Take(batchSize);
var valuesToInsert = userToInsert.Select(u => string.Format(valuesSql, u));
sqlsToExecute.Add(insertSql + string.Join(',', valuesToInsert));
}
return sqlsToExecute;
}
Lets compare!
Code is nice and tidy, but is it faster? To check it I uesd a local database and a simple users name generator. It’s just a random, 10 character string.
public async Task<JsonResult> InsertInBulk(int? number = 100)
{
var userNames = new List<string>();
for (int i = 0; i < number; i++)
{
userNames.Add(RandomString(10));
}
var stopwatch = new Stopwatch();
stopwatch.Start();
await _usersRepository.InsertInBulk(userNames);
stopwatch.Stop();
return Json(
new
{
users = number,
time = stopwatch.Elapsed
});
}
I tested this code for 100, 1000, 10k and 100k. Results surprised me.
The more users I added, the best performance gain I got. For 10k users it 42x and for 100k users it’s 48x improvement in performance. This is awesome!
It’s not safe
Immediately after posting this article, I got comments from you, that this code is not safe. Joining raw strings like that in a SQL statement is a major security flaw, cause it’s exposed for SQL injection. And that is something we need to take care of. So I came up with the code, that Nicholas Paldino suggested in his comment. I used DynamicParameters to pass values to my sql statement.
public async Task SafeInsertMany(IEnumerable<string> userNames)
{
using (var connection = new SqlConnection(ConnectionString))
{
var parameters = userNames.Select(u =>
{
var tempParams = new DynamicParameters();
tempParams.Add("@Name", u, DbType.String, ParameterDirection.Input);
return tempParams;
});
await connection.ExecuteAsync(
"INSERT INTO [Users] (Name, LastUpdatedAt) VALUES (@Name, getdate())",
parameters).ConfigureAwait(false);
}
}
This code works fine, however it’s performance is comparable to regular approach. So it is not really a way to insert big amounts of data. An ideal way to go here is to use SQL Bulk Copy and forget about Dapper.
I know that there is a commercial Dapper extension, that helps with bulk operations. You can have a look here. But wouldn’t it be nice, to have a free nuget package for it? What do you think?
Recently I’m diving into Microsoft actor model implementation – Service Fabric Reliable Actors. Apart from Microsoft Orleans, is another one worth looking into. Let’s start from the beginning.
What is Service Fabric? It is many things and can be compared to Kubernetes:
Simplify microservices development and application lifecycle management
Reliably scale and orchestrate containers and microservices
Data-aware platform for low-latency, high-throughput workloads with stateful containers or microservices
Run anything – your choice of languages and programming models
Run anywhere – supports Windows/Linux in Azure, on-premises, or other clouds
From my perspective, it is just another way to manage micro-services. It can be set up on Azure or on-premise. Its biggest disadvantage is it’s dashboard, that does not offer much, comparing to IIS or Azure.
What are Reliable Actors? It is a Service Fabric implementation of an actor pattern, that is great for handling many small parallel operations. Actor, in this case, is a small piece of business logic, that can hold state and all actors can work simultaneously and independently, no matter if there is a hundred or hundred thousand of them.
If you’re new to actor model, you can have a look at an introduction to Microsoft Orleans. It covers all the basics: Getting started with Microsoft Orleans
Scenario
Let’s have an example to understand how all of this can be used in practice.
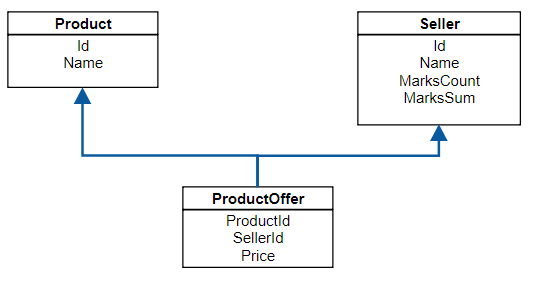
Let’s build price comparer micro-service, that will maintain sellers, products and offers for products. Every seller can have many offers for many products and every product will have many offers from many sellers. Something that in DB will look like this:
The main features of this service are:
it is a REST micro-service, so all communication will go through it’s API
it needs to persist its state
when getting a product, it needs to respond with json, where offers are sorted by seller rating descending
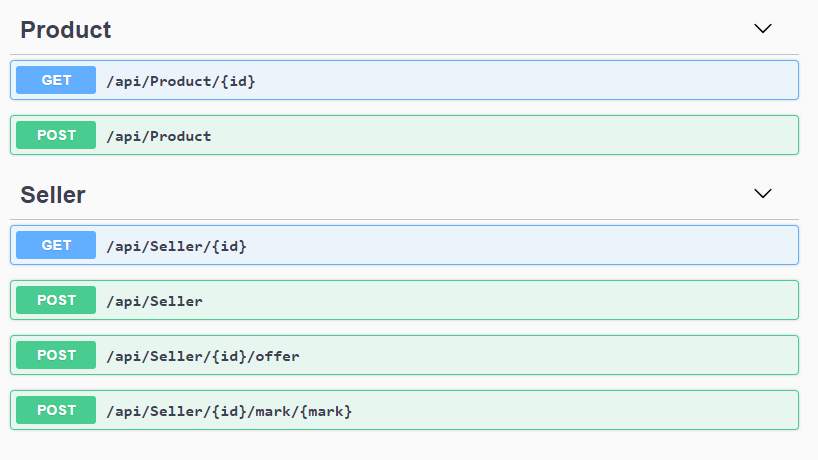
The last requirement forces us to update product offers whenever seller rating changes. Whenever seller rating changes, all its product offers need to be reordered. It sounds complicated, but it’s easier than it seems. API looks like this:
And Json that we would like to get in return, looks like this:
Simple micro-service approach
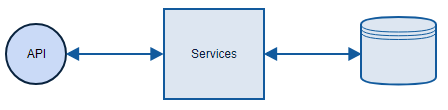
I already showed you how DB model can look like and this is precisely the way I’m going to implement it. Every operation will go to DB and take data from there. The architecture will be simple:
Of course I might keep my state in memory and update it whenever something changes, but this is rather difficult. In fact, cache invalidation is told to be one of the two hardest problems in software development. Right after naming things.
Let’s have a look how SellerController is built, it’s rather simple:
public class SellerRepository : ISellerRepository
{
private const string RemoveSeller = @"DELETE FROM Seller WHERE Id = @Id";
private const string InsertSeller = @"INSERT INTO Seller (Id, Name, MarksCount, MarksSum) VALUES (@Id, @Name, @MarksCount, @MarksSum)";
private const string UpdateSellerRating = @"UPDATE Seller SET MarksCount = @MarksCount, MarksSum = @MarksSum WHERE Id = @Id";
private const string GetSeller = @"SELECT Id, Name, MarksCount, MarksSum FROM Seller WHERE Id = @id";
private const string GetSellerOffers = @"SELECT ProductId, Price FROM ProductOffer WHERE SellerId = @id";
private readonly IConfigurationRoot _configuration;
public SellerRepository(IConfigurationRoot configuration)
{
_configuration = configuration;
}
public async Task Save(Seller seller)
{
using (var connection = new SqlConnection(_configuration.GetConnectionString("DbConnectionString")))
{
await connection.ExecuteAsync(RemoveSeller, new { seller.Id });
await connection.ExecuteAsync(InsertSeller, seller);
}
}
public async Task<Seller> Get(string id)
{
using (var connection = new SqlConnection(_configuration.GetConnectionString("DbConnectionString")))
{
var sellerOffers = await connection.QueryAsync<Offer>(GetSellerOffers, new { id });
var seller = await connection.QuerySingleAsync<Seller>(GetSeller, new { id });
seller.Offers = sellerOffers.ToList();
return seller;
}
}
public async Task Update(Seller seller)
{
using (var connection = new SqlConnection(_configuration.GetConnectionString("DbConnectionString")))
{
await connection.ExecuteAsync(UpdateSellerRating, seller);
}
}
}
To be able to use code like this:
connection.QuerySingleAsync<Seller>(GetSeller, new { id })
I used Dapper nuget package – very handy tool that enriches simple IDbConnection with new features.
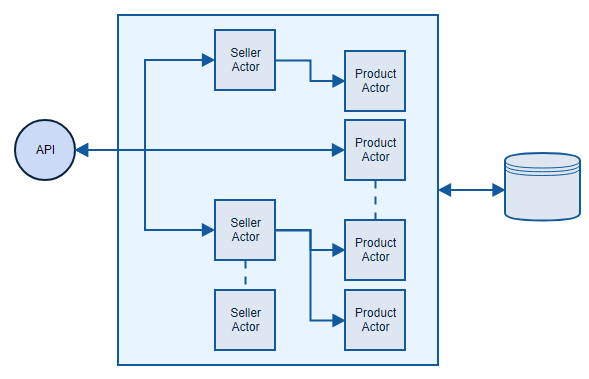
Service Fabric approach
The functionality of Service Fabric implementation will be exactly the same. Small micro-service that exposes REST API and ensures that state is persistent. And this is where similarities end. First, let’s have a look at the project structure:
From the top:
MichalBialecki.com.SF.PriceComparer – have you noticed Service Fabric icon? It contains configuration how to set up SF cluster and what application should be hosted. It also defines how they will be scaled
PriceComparer – Business logic for API project, it contains actor implementation
PriceComparer.Api – REST API that we expose. Notice that we also have ServiceManifest.xml that is a definition of our service in Service Fabric
PriceComparer.Interfaces – the name speaks for itself, just interfaces and dtos
Controller implementation is almost the same as in the previous approach. Instead of using repository it uses actors.
ActorProxy.Create<ISellerActor> is the way we instantiate an actor, it is provided by the framework. Implementation of SellerActor needs to inherit Actor class. It also defines on top of the class how the state will be maintained. In our case it will be persisted, that means it will be saved as a file on a disk on the machine where the cluster is located.
[StatePersistence(StatePersistence.Persisted)]
internal class SellerActor : Actor, ISellerActor
{
private const string StateName = nameof(SellerActor);
public SellerActor(ActorService actorService, ActorId actorId)
: base(actorService, actorId)
{
}
public async Task AddSeller(Seller seller, CancellationToken cancellationToken)
{
await StateManager.AddOrUpdateStateAsync(StateName, seller, (key, value) => value, cancellationToken);
}
public async Task<Seller> GetState(CancellationToken cancellationToken)
{
return await StateManager.GetOrAddStateAsync(StateName, new Seller(), cancellationToken);
}
public async Task AddOffer(Offer offer, CancellationToken cancellationToken)
{
var seller = await StateManager.GetOrAddStateAsync(StateName, new Seller(), cancellationToken);
var existingOffer = seller.Offers.FirstOrDefault(o => o.ProductId == offer.ProductId);
if (existingOffer != null)
{
seller.Offers.Remove(existingOffer);
}
seller.Offers.Add(offer);
var sellerOffer = new SellerOffer
{
ProductId = offer.ProductId,
Price = offer.Price,
SellerId = seller.Id,
SellerRating = seller.Rating,
SellerName = seller.Name
};
var productActor = ActorProxy.Create<IProductActor>(new ActorId(offer.ProductId));
await productActor.UpdateSellerOffer(sellerOffer, cancellationToken);
await StateManager.SetStateAsync(StateName, seller, cancellationToken);
}
public async Task Mark(decimal value, CancellationToken cancellationToken)
{
var seller = await StateManager.GetOrAddStateAsync(StateName, new Seller(), cancellationToken);
seller.MarksCount += 1;
seller.MarksSum += value;
await StateManager.SetStateAsync(StateName, seller, cancellationToken);
foreach (var offer in seller.Offers)
{
var productActor = ActorProxy.Create<IProductActor>(new ActorId(offer.ProductId));
await productActor.UpdateSellerRating(seller.Id, seller.Rating, cancellationToken);
}
}
}
Notice that in order to use state, we use StateManager, also provided by the framework. The safest way is to either user GetOrAddStateAsync or SetStateAsync. Fun fact – all methods are asynchronous, there are no sync ones. There is a good emphasis on making code async, so that it can be run better in parallel with other jobs.
Take a look at Mark method. In order to mark a seller, we need to get its state, increment counters and save state. Then we need to update all product offers that seller has. Let’s take a look at how updating product looks like:
public async Task UpdateSellerRating(string sellerId, decimal sellerRating, CancellationToken cancellationToken)
{
var product = await StateManager.GetOrAddStateAsync(StateName, new Product(), cancellationToken);
var existingMatchingOffer = product.Offers.FirstOrDefault(o => o.SellerId == sellerId);
if (existingMatchingOffer != null)
{
existingMatchingOffer.SellerRating = sellerRating;
product.Offers = product.Offers.OrderByDescending(o => o.SellerRating).ToList();
await StateManager.SetStateAsync(StateName, product, cancellationToken);
}
}
We are updating seller rating in his offer inside a product. That can happen for thousands of products, but since this job is done in different actors, it can be done in parallel. Architecture for this approach is way different when compared to simple micro-service.
Comparison
To compare both approaches I assumed I need a lot of data, so I prepared:
1000 sellers having
10000 products with
100000 offers combined
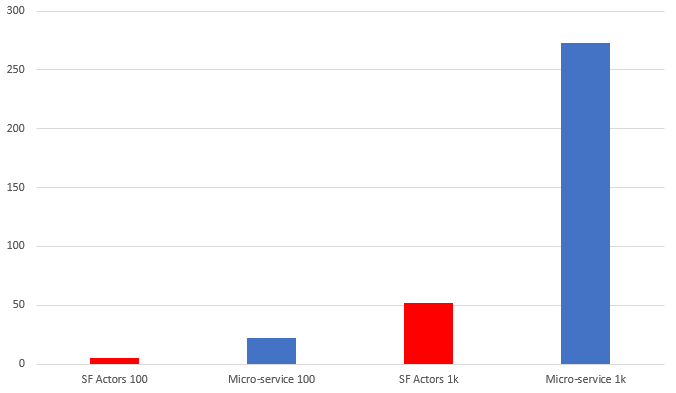
It sounds a lot, but in a real-life price comparer, this could be just a start. A good starting point for my test, though. The first thing that hit me was loading this data into both services. Since both approaches exposed the same API, I just needed to make 11000 requests to initialize everything. With Service Fabric it all went well, after around 1 minute everything was initialized. However with simple DB approach… it throws SQL timeout exceptions. It turned out, that it couldn’t handle so many requests, even when I extended DB connection timeout. I needed to implement batch init, and after a few tries, I did it. However, the time that I needed to initialize all the data wasn’t so optimistic.
First two columns stand for initializing everything divided by 10, and second two stands for full initialization. Notice that a simple DB approach took around 5 times more than Service Fabric implementation!
To test the performance of my services I needed to send a lot of requests at the same time. In order to do that I used Locust – a performance load tool. It can be easily installed and set up. After preparing a small file that represents a testing scenario, I just run it from the terminal and then I can go to its dashboard, that is accessible via a browser.
Let’s have a look at how the performance of the first approach looks like. In this case, Locust will simulate 200 users, that grows from 0 to 200, 20 users per second. It will handle around 30 requests per second with an average response time 40 ms. When I update that value to 400 users, it will handle around 50 requests per minute, but response time will go to around 3 seconds. That, of course, is not acceptable in micro-service development.
The second video shows the same test, but hitting Service Fabric app. This time I’d like to go bold and start off with 1000 users. It will handle around 140 RPM with an average response time around 30ms, which is even faster than 400 users and first approach. Then I’ll try 2000 users, have a look:
Summary
I showed you two approaches, both written in .Net Core 2.0. The first one is a very simple one using SQL DB, and the second one is Service Fabric with Reliable Actors. From my tests, I could easily see that actors approach is way more performant. Probably around 5 times in this specific case. Let’s point this out:
Pros:
very fast in scenarios, where there are many small pieces of business logic, tightly connected to data
trivial to try and implement – there is a Visual Studio project for that
Cons:
It’s more complicated to implement than the regular approach
Configuring Service Fabric with XML files can be frustrating
Since everything handled by the framework, a developer has a bit less control over what’s happening