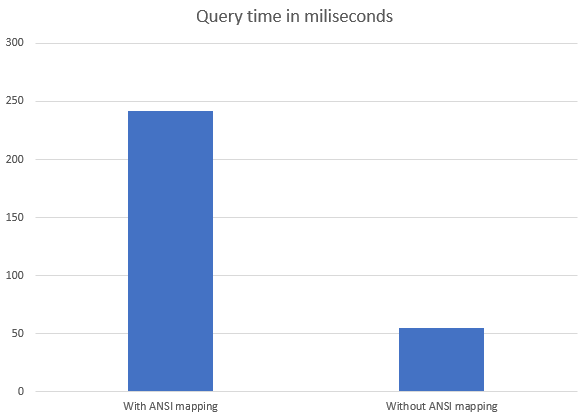
Entity Framework Core is a great ORM, that recently reached version 5. Is it fast? Is it faster than it’s predecessor, Entity Framework 6, which still offers slightly more functionality? Let’s check that out.
This comparison was made by Chad Golden, comparing the performance of adding, updating, and deleting 1000 entities. The exact data and code are available on his blog: https://chadgolden.com/blog/comparing-performance-of-ef6-to-ef-core-3
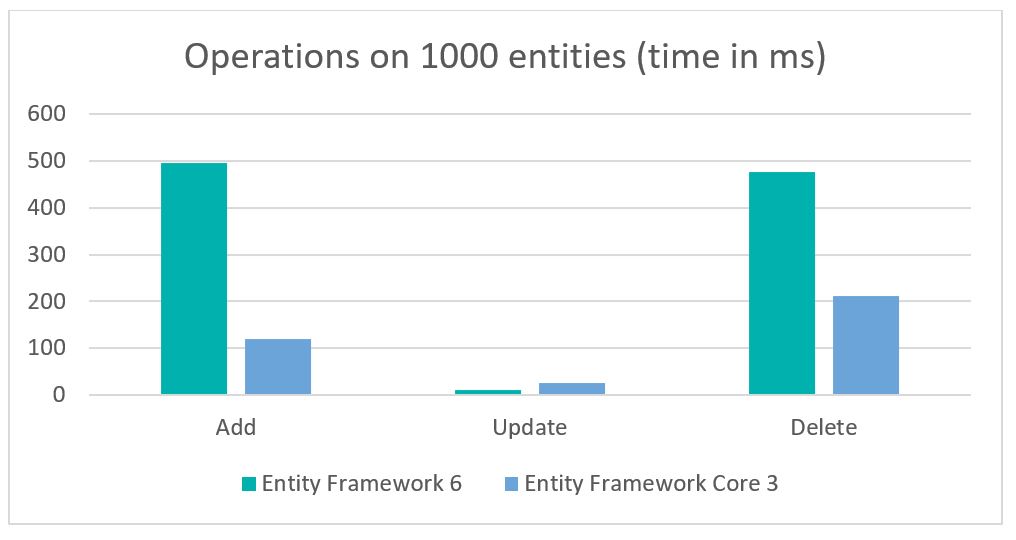
The conclusions are obvious: in almost every test conducted by Chad, Entity Framework Core 3 is faster than Entity Framework 6 – exactly 2.25 to 4.15 times faster! So if performance is important to your application and it operates on large amounts of data, EF Core should be a natural choice.
Is it faster than Dapper?
Dapper is a very popular object-relational mapper and, like EF Core, it facilitates working with the database. It’s called the king of Micro ORM because it’s very fast and does some of the work for us. If we compare EF Core and Dapper, we immediately notice that the capabilities of EF Core are much greater. Microsoft technology allows you to track objects, migrate the database schema, and interact with the database without writing SQL queries. Dapper, on the other hand, maps the objects returned by the database, but all SQL commands have to be written yourself. This certainly allows more freedom in operating the database, but there is a greater risk of making a mistake when writing a SQL query. Similarly to updating the database schema, EF Core can create changes and generate a migration by itself, and in Dapper, you have to manually edit the SQL code.
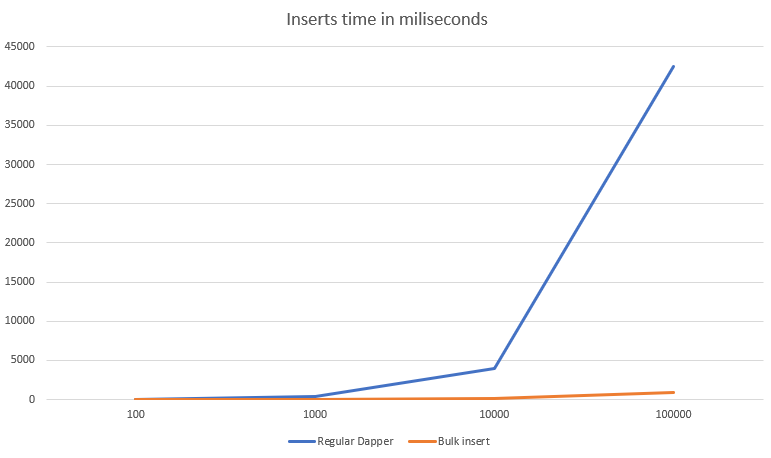
There is no doubt, however, that Dapper has its supporters, mainly due to its performance. On the blog exceptionnotfound.net we can find a comparison between Entity Framework Core 3 and Dapper version 2.
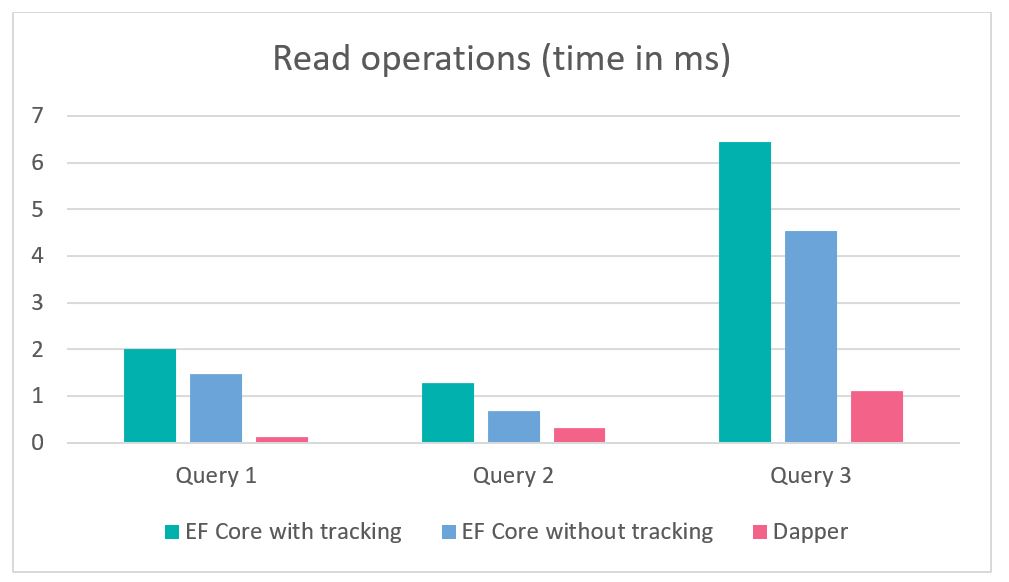
As you can see, we compare 3 database reads here, where Entity Framework Core with object tracking in one case, non-tracking in the other, and Dapper’s third. Tracking changes to entities in EF Core can be turned off with the AsNoTracking() option, which makes reading operations significantly faster. More information on this test can be found here: https://exceptionnotfound.net/dapper-vs-entity-framework-core-query-performance-benchmarking-2019/
Summary
All in all – Dapper is much faster to read from the database and will certainly be comparatively fast when writing. However, it requires writing SQL queries, which can expose the developer to errors. I have personally used Dapper on several projects, and basically, only one has been dictated by performance. For the simple logic of saving and retrieving data from the database, I would use Entity Framework Core because of its simplicity and convenience in introducing changes.