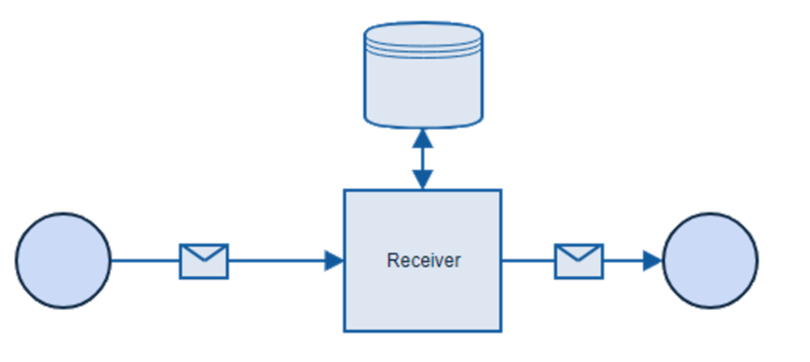
It may seem that when creating a console application we are doomed to use statics all over the code. Well.. we’re not! I’ll show you how to set up dependency injection and use it.
This is a part of a series of articles about writing a perfect console application in .net core 2. Feel free to read more:
There are many packages that can provide dependency injection, but I chose SimpleInjector, because I know it well. It’s also quite fast, according to Daniel Palme’s article. Here is how whole calss looks like:
using System.Linq;
using SimpleInjector;
public static class ContainerConfig
{
private static Container Container;
public static void Init()
{
Container = new Container();
RegisterAllTypesWithConvention();
Container.Verify();
}
public static TService GetInstance<TService>() where TService : class
{
return Container.GetInstance<TService>();
}
private static void RegisterAllTypesWithConvention()
{
var typesWithInterfaces = typeof(Program).Assembly.GetExportedTypes()
.Where(t => t.Namespace.StartsWith("MichalBialecki.com.TicketStore"))
.Where(ts => ts.GetInterfaces().Any() && ts.IsClass).ToList();
var registrations = typesWithInterfaces.Select(ti => new
{
Service = ti.GetInterfaces().Single(), Implementation = ti
});
foreach (var reg in registrations)
{
Container.Register(reg.Service, reg.Implementation, Lifestyle.Singleton);
}
}
}
Notice RegisterAllTypesWithConvention method – it is the way to register all interface implementations, that follows a simple naming convention. When interface will have an additional I in the name comparing to it’s class implementation, then it will be automatically registered. No need to remember about such silly things now!
From an early development age, I was taught, that duplication is a bad thing. Especially when it comes to storing data. Relational databases were invented to show data that relates to each other and be able to store them efficiently. There are even a few normalization rules, to be able to avoid data redundancy. We are slowly abandoning this approach to non-relational databases because of their simplicity and storage price reduction. Nevwrtheless, having the same thing in two places leads to ambiguity and chaos. It also refers to DRY rule:
DRY – don’t repeat yourself. Every piece of knowledge must have a single, unambiguous, authoritative representation within a system. (Wikipedia)
The concept of breaking DRY rule is called WET, commonly taken to stand for either “write everything twice”, “we enjoy typing” or “waste everyone’s time”. This isn’t nice, right? So when duplication is acceptable?
Let’s look at the example.
In this example, we see a network of stateful services that exchange data about products. Data can came from many sources and we need to send them to many destinations. Data flow from one service to another. Here are a couple of rules:
every micro-service has data about its own specific thing and keeps it persistent
services work in a publisher-subscriber model, where every service can publish the data and receive the data it needs
services don’t know about each other
Does this sounds familiar?
Event-driven microservices
Event-driven programming isn’t a new thing, which we can check in Wikipedia. It is a program, where the flow of the program is triggered by events. It is extensively used in graphical user interfaces and web applications, where user interactions trigger program execution.
Every major platform supports event-driven programming, there is AWS Lambda by Amazon, Azure Functions by Microsoft and Google Cloud Functions by Google. All of those technologies offer event triggering.
In back-end micro-services, an event can be for example a web request or a service bus message. Let’s use Service Bus messages, where every service will be connected to the bus and can act both as a publisher and subscriber.
In this architecture usage of Service Bus is crucial, because it provides some distinctive features:
services are lously coupled, they don’t know about each other. Building another micro-service that needs specific data is just a matter of subscribing to right publishers
it’s good for scalability – it doesn’t matter if 1 or 10 instances of services subscribes to a certain topic – it will work without any code change
it can handle big load – messages will be kept in a queue and service can consume it in its own pace
it has build-in mechanisms for failure – if message could not be processed, it will be put back to the queue for set amount of times. You can also specify custom retry policy, that can exponentialy extend wait time between retries
If you’d like to know more about Microsoft Service Bus in .Net Core, jump to my blog posts:
When we notice that there might be something fishy going on with or micro-service, we have to be able to fix it. It might miss some data, but how to know exactly what data this micro-service should have? When micro-services are stateful, we have whole state saved in every one of them. This means, that we can make other services send data to one in failed state. Or even better – tell a service to fix itself!
You can see how a micro-services state can be fixed by a single admin request. Service can get all of the data only because other services are stateful. This came in handy not always in crisis situations, but also when debugging. Investigating stateless services when you actually don’t know what data came in and what came out can be really painful.
But it’s data duplication!
That’s right! In the mentioned scenario each micro-service is stateful and have its own database. Apart from all the good things I mention I just need to add, that those services are small and easy to maintain. However, they could be merged into one bigger micro-service, but that wouldn’t micro service anymore, would it? Also when services have less to do, they also work faster.
Ok, but back to the problem. It’s data duplication! With a big D! Almost all services share some parts of the same thing, how do we know which one is correct and which one to use? The answer is simple: keep data everywhere, but use only one source.
Single source of truth – it is one source for getting certain data. Whenever you want some data that are consistent and up-to-date, you need to take it from the source of truth. It guarantees that when two clients request the data at the same time, they will get the same result. This is very important in a distributed system, where one client can feed data on a product page showing titles and prices and another one should show the same data in a cart or checkout.
In our examplesingle source of truth for products would be Product Service, and for marketing content would be Marketing Content Service.
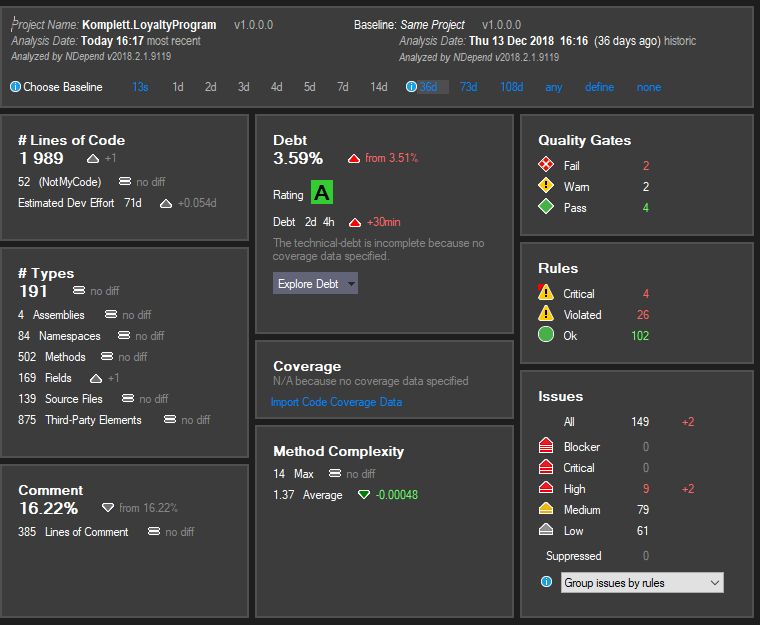
Recently I got my hands on NDepend, a static code analysis tool for .Net framework. Because it can work as a plugin for Visual Studio, it offers great integration with code and rapid results. So what it can do? Let’s see!
Getting started
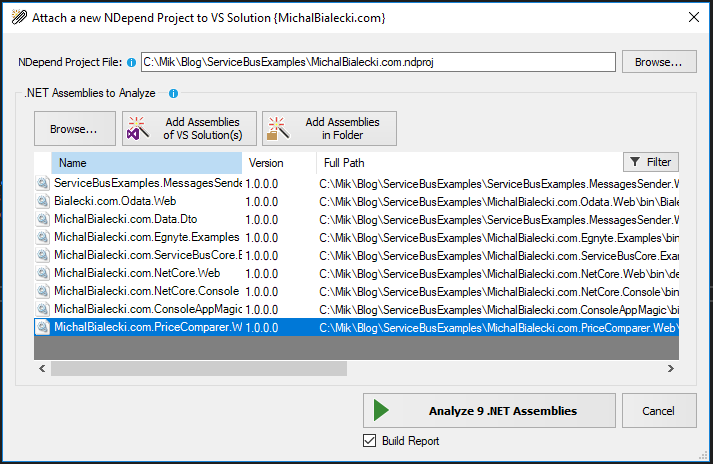
To start working with NDepend you need to download it and install for your Visual Studio. It’s not a free tool, but you can choose to start a 14-day trial period. Then you need to attach a new NDepend project.
And choose assemblies to analyze.
Then wait a few seconds… and voila! You can see a dashboard with results or full HTML report.
What does it mean?
NDepend analyses code in many ways, checking if it is written in a correct way. In the top, you can see that it compared code to the one from 36 days and shows how it has changed. Let’s have a look at some of the results:
Lines of Code – this is a number of logical lines of code, so code that contains some logic. Quoting the website: “Interfaces, abstract methods, and enumerations have a LOC equals to 0. Only concrete code that is effectively executed is considered when computing LOC”
Debt – an estimation of the effort needed to fix issues. A debt-ratio is obtained by comparing the debt with an estimation of the effort needed for the development of the analyzed code, hence the percentage. Those are numbers that you can use to compare different versions of your app and also plan refactorings
Types – apart from LOC, shows how big is your project and how big is the recent change
Comment – comments code coverage
Quality gates – overall check that should suggest that this code is good enough to proceed with it (for example to merge it)
Rules – shows what rules are violated and their level
Issues – problems with your code, that needs an attention
To clear this our – you might have 149 issues, that categorize into 30 failing rules and that can result in two main quality gates failure.
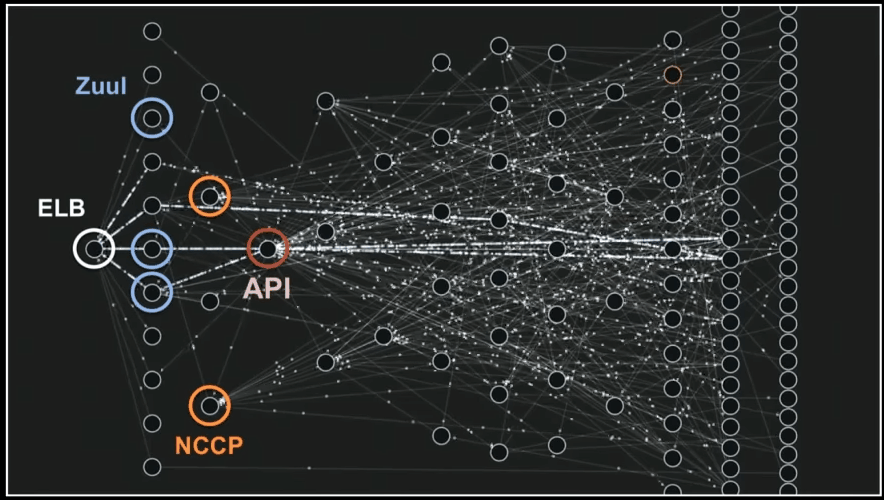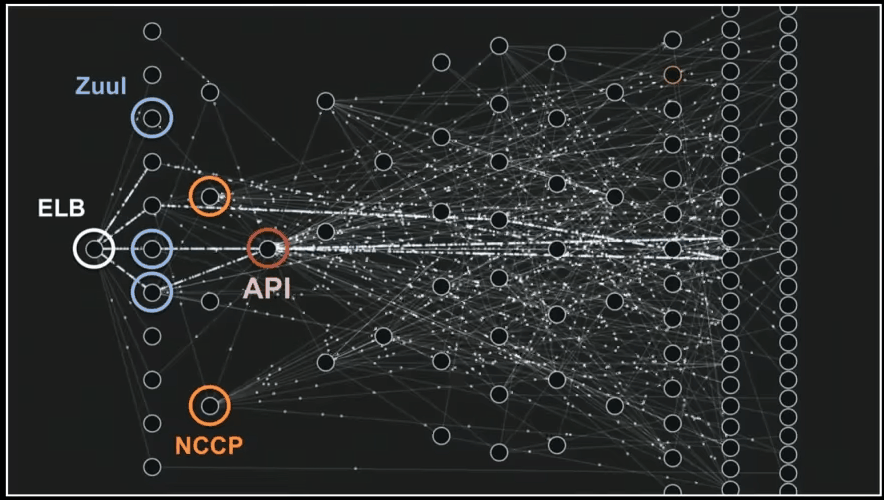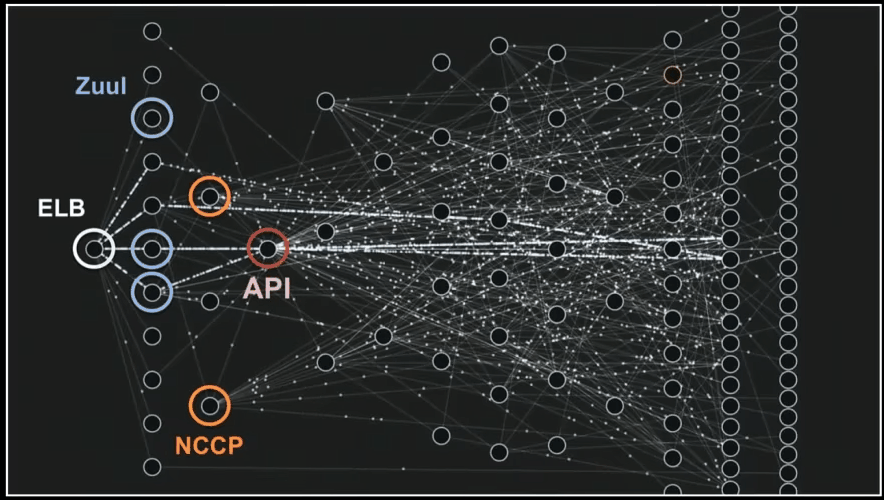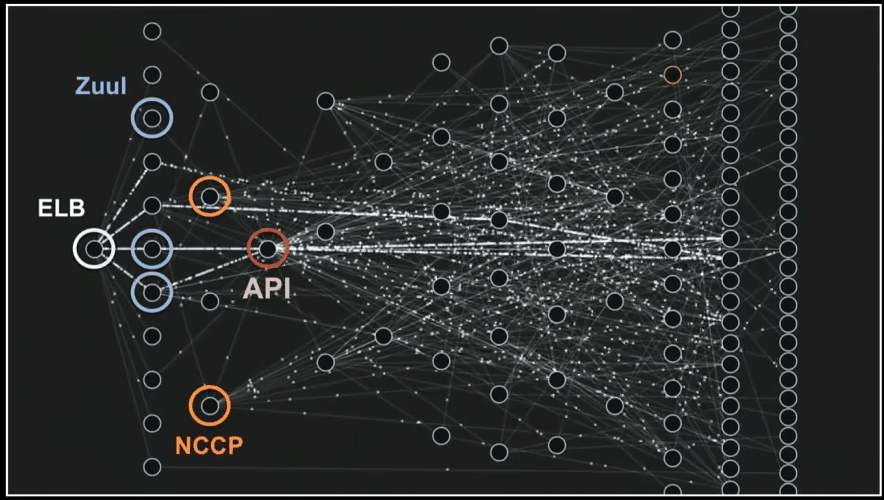
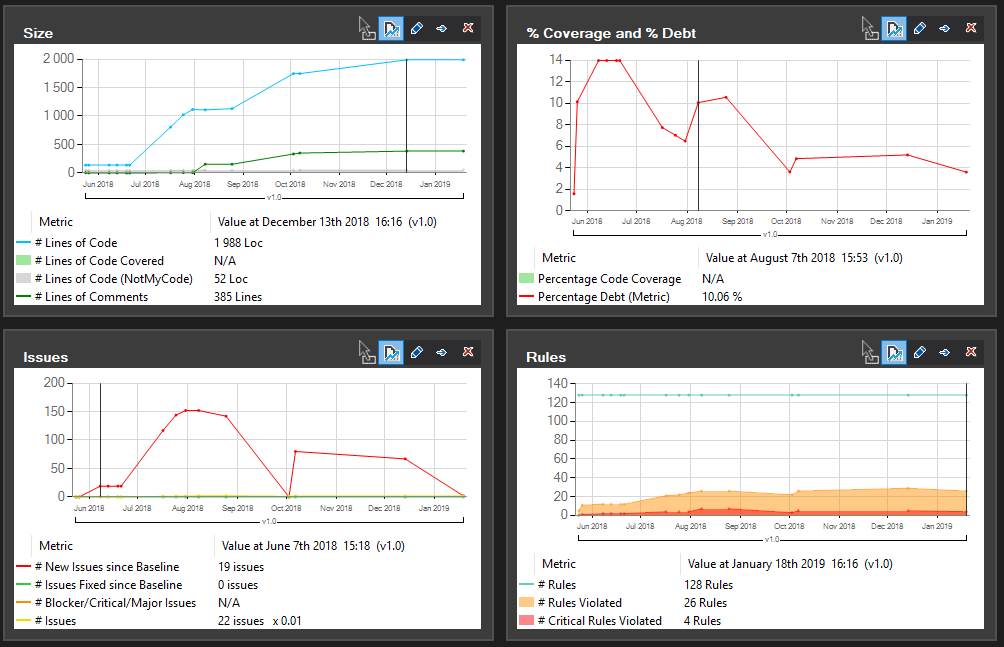
It’s getting more interesting if you analyze your project on a day to day basis and you start to notice some trends and effects of recent changes. This is an insight that you cannot measure even if you’re very well accustomed to the project. Let’s look at the analysis for a small micro-service over its whole life – a few months. You could see the dashboard already, so here are some charts.
You can see how the project is getting bigger and how the number of issues is rising and then dropping. This is a normal phase of software development, where you code first and fix bugs later. You can also see that we started to write comments after a few months of project development.
The report
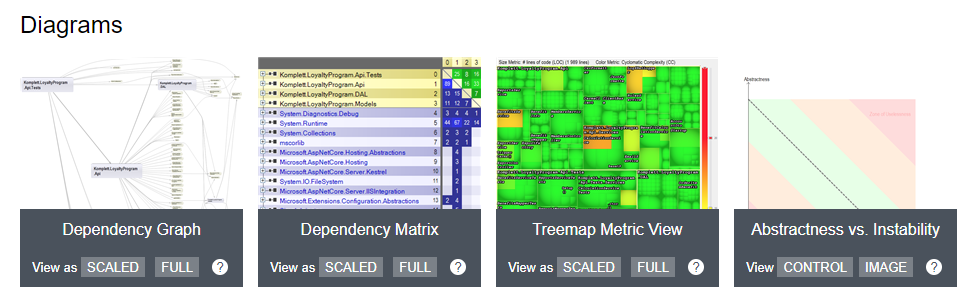
Along with the analysis, NDepend created a full HTML report that presents event more data.
There are some useful diagrams:
Dependency Graph – shows you how your assemblies are connected to each other
Dependency Matrix – sums up all dependencies and you can easily see which assemblies have way too much responsibility
Treemap Metric View – shows in a colorful way what namespaces have issues
Abstractness vs. Instability – points what assembly in your solution might need an attention
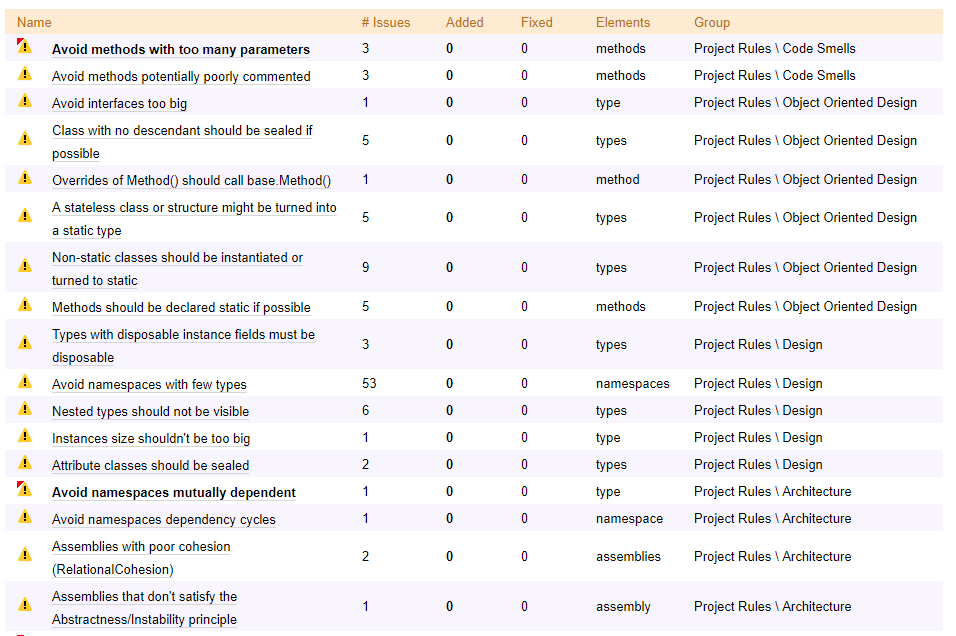
The report also lists rules that are violated by your app.
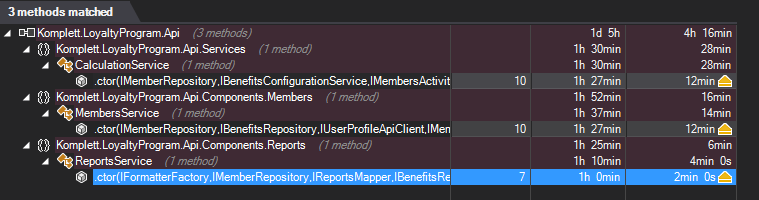
There are many rules that check our code. From Object-Oriented Programming and potential code smells to best practices in design and architecture. In Visual Studio you can see that same report as well and you can easily navigate to code that has problems. Let’s click on the first one: avoid methods with too many parameters.
Then we can go inside by double clicking to see places in the code that applies.
In this example, the constructor has too many parameters – 10 in this example. This might mean, that those classes have too much responsibility and might need refactoring. Also writing tests for it might be challenging.
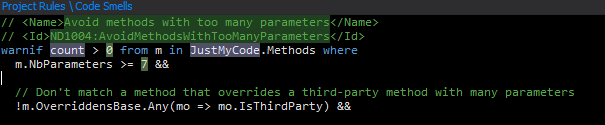
What is cool about NDepend is that every rule can be customized and edited, cause it is written in C#. We can have a quick look at this rule and check how many parameters in a method is good enough.
So 7 is the number here 🙂 Methods with 6 parameters are ok.
What is it for?
I showed you that this tool can analyze code and show some advanced metrics, but what I can use it for in my project?
Finds code smells – it’s ideal for identifying technological debt, that needs fixing. When planning a technical sprint, where you only polish the code, this tool will be perfect to spot any flaws
It’s quick – you can easily analyze a new project and check if it is written following good practices
Shows progress – you can track how you codebase quality changes while you’re changing the code
That last point surprised me. Some time ago I was making a quite big refactoring in a legacy project. I was convinced that deleting a lot of difficult code and introducing simpler, shorter classes will dramatically improve codebase quality. In fact, technological debt grew a little bit, because I didn’t follow all good practices. While old code seemed as unlogical and hard to debug, the new one is just easier to understand, because I wrote it.
It shocked me
I used NDepend on a project I’m proud of, which I was involved in from the beginning and I used a lot of time to make it as close to perfection as it was possible in a reasonable time. As a group of senior developers, we almost always find something during a code review, that could be done better or just can be discussed. I was sure that code is really good. How shocked I was when I found out, that NDepend didn’t fully agree. The project did get an A rating, but there were still a few things that could have been done better. And this is its real value.
Would I recommend it?
I need to admit, that I got an NDepend license for free to test it out. If it wasn’t for Patrick Smacchia from NDepend, I wouldn’t discover that anytime soon. And I would never learn, that no matter how good you get in your work, you always can do better.
I recommend you to try NDepend yourself and brace yourself… you might be surprised 🙂
I’m working in a solution, that has many micro-services and some of them share the same DTOs. Let’s say I have a Product dto, that is assembled and processed through 6 micro-services and all of them has the same contract. In my mind an idea emerged:
Can I have a place to keep this contract and share across my projects?
And the other thoughts came to my mind:
It can be distributed as a NuGet package!
I’ll update it once and the rest is just using it.
It will always be correct, no more typos in contracts that lead to bugs.
And boy I was lucky not to do so.
After some time I had to extend my contract – that was fine. But while services where evolving over time, Product started to mean different things in those services. In one it was just Product, that represents everything, in others it was Product coming from that specific data source. There were CustomProduct, LeasingProduct and ExtendedProduct as well. And I’m not mentioning DigitalProduct, BonusProduct, DbProduct,ProductDto, etc.
The thing is that a group of services might use the same data, but it doesn’t mean that they are in the same domain.
What is wrong with sharing a contract between different domains?
Classes and fields mean different things in a different domain. So the name Product for everything isn’t perfect. Maybe in some domain, more specific name will be more accurate
Updating contract with non-breaking changes is fine, but introducing breaking change will always require supervision. When it’s a nuget package, it’s just easy to update package without thinking about consequences
When we receive a contract and we do not need all of it, we can just specify fields we actually need. This way receiving and deserializing an object is a bit faster
When extending a shared contract as NuGet package we immediately see in a receiver that something changed and we need to update it and do some work on our side, where normally we wouldn’t care to update contract, as long as we need it
When having a contract in a NuGet package can be beneficial? For example when we need exactly this contract to communicate with something. For example, a popular service can share it’s client and DTOs as a NuGet package to ease integration with it.
And what do you think? Is is a good thing, or a bad thing?
This is one of the proof of concent that I did at work. The idea was to add another Service Bus application to an existing solution, instead of starting a whole new micro-service. It was a lot faster just to add another .net core console application, but setting up Service Fabric cluster always brings some unexpected experiences.
What are my requirements:
everything has to be written in .Net Core
reading Service Bus messages is placed in a new console application
logging has to be configured
dependency injection needs to be configured
reading Service Bus messages needs to be registered in stateless service
Let’s get to work!
The entry point in console application
Console application are a bit specific. In most cases, we write console applications that are small and doesn’t require dependency injection or logging, apart from that to the console. But here I want to build a professional console application, that is not run once, but is a decent part of a bigger thing that we would need to maintain in the future.
The specific thing about console applications is that they have Main method and this method is run instantly after the execution and everything that you’d like to do, has to be there. That means, that both configuration and execution of an app needs to be in this one method. Let’s see how the code looks like:
Here is a place where I configure IoC container. It has to be done here, cause only when registering a Service Fabric service, we have an instance of StatelessServiceContext, that we need later.
Configuring IoC container
In order to have container implementation provided by the framework, just install Microsoft.Extensions.DependencyInjection nuget package. ContainerConfig class, in this case, looks like this:
public static class ContainerConfig
{
private static ServiceProvider ServiceProvider;
public static void Init(
StatelessServiceContext context,
IConfigurationRoot configuration)
{
ServiceProvider = new ServiceCollection()
.AddLogging()
.AddSingleton(context)
.AddSingleton<ServiceBusStatelessService>()
.AddSingleton<IServiceBusCommunicationListener, ServiceBusCommunicationListener>()
.AddSingleton<IConfigurationRoot>(configuration)
.BuildServiceProvider();
}
public static TService GetInstance<TService>() where TService : class
{
return ServiceProvider.GetService<TService>();
}
}
Adding a stateless service
In Program class I registered ServiceBusStatelessService class, that looks like this:
public class ServiceBusStatelessService : StatelessService
{
private readonly IServiceBusCommunicationListener _serviceBusCommunicationListener;
public ServiceBusStatelessService(StatelessServiceContext serviceContext, IServiceBusCommunicationListener serviceBusCommunicationListener)
: base(serviceContext)
{
_serviceBusCommunicationListener = serviceBusCommunicationListener;
}
protected override IEnumerable<ServiceInstanceListener> CreateServiceInstanceListeners()
{
yield return new ServiceInstanceListener(context => _serviceBusCommunicationListener);
}
}
ServiceBusStatelessService inherits from StatelessService and provides an instance of Service Bus listener. It looks like this:
public class ServiceBusCommunicationListener : IServiceBusCommunicationListener
{
private readonly IConfigurationRoot _configurationRoot;
private readonly ILogger _logger;
private SubscriptionClient subscriptionClient;
public ServiceBusCommunicationListener(IConfigurationRoot configurationRoot, ILoggerFactory loggerFactory)
{
_logger = loggerFactory.CreateLogger(nameof(ServiceBusCommunicationListener));
_configurationRoot = configurationRoot;
}
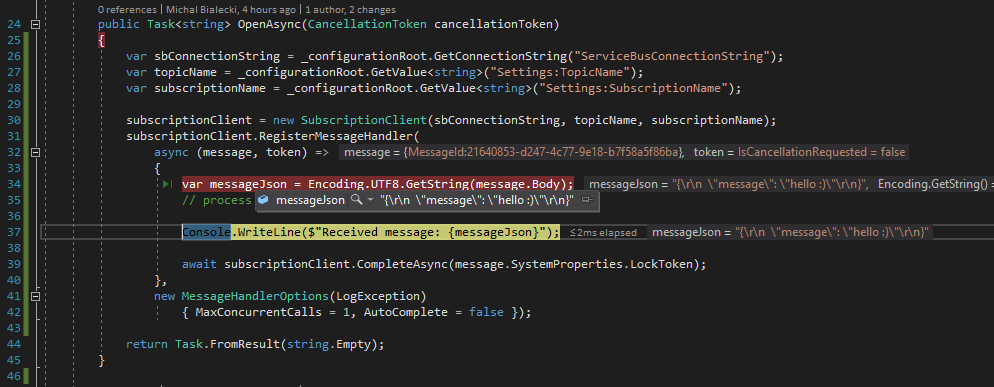
public Task<string> OpenAsync(CancellationToken cancellationToken)
{
var sbConnectionString = _configurationRoot.GetConnectionString("ServiceBusConnectionString");
var topicName = _configurationRoot.GetValue<string>("Settings:TopicName");
var subscriptionName = _configurationRoot.GetValue<string>("Settings:SubscriptionName");
subscriptionClient = new SubscriptionClient(sbConnectionString, topicName, subscriptionName);
subscriptionClient.RegisterMessageHandler(
async (message, token) =>
{
var messageJson = Encoding.UTF8.GetString(message.Body);
// process here
Console.WriteLine($"Received message: {messageJson}");
await subscriptionClient.CompleteAsync(message.SystemProperties.LockToken);
},
new MessageHandlerOptions(LogException)
{ MaxConcurrentCalls = 1, AutoComplete = false });
return Task.FromResult(string.Empty);
}
public Task CloseAsync(CancellationToken cancellationToken)
{
Stop();
return Task.CompletedTask;
}
public void Abort()
{
Stop();
}
private void Stop()
{
subscriptionClient?.CloseAsync().GetAwaiter().GetResult();
}
private Task LogException(ExceptionReceivedEventArgs args)
{
_logger.LogError(args.Exception, args.Exception.Message);
return Task.CompletedTask;
}
}
Notice, that all the work is done in OpenAsync method, that is run only once. In here I just register standard message handler, that reads from a Service Bus Subscription.
Configure Service Fabric cluster
All Service Fabric configuration is done in xml files. This can cause a huge headache when trying to debug and find errors, cause the only place you can find fairly useful information is console window.
It starts with adding a reference in SF project to a console application.
Next this is to have right name in console application ServiceManifest.xml
<?xml version="1.0" encoding="utf-8"?>
<ServiceManifest Name="MichalBialecki.com.SF.ServiceBusExample.MessageProcessorPkg"
Version="1.0.0"
xmlns="http://schemas.microsoft.com/2011/01/fabric"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<ServiceTypes>
<!-- This is the name of your ServiceType.
This name must match the string used in the RegisterServiceAsync call in Program.cs. -->
<StatelessServiceType ServiceTypeName="MichalBialecki.com.SF.ServiceBusExample.MessageProcessorType" />
</ServiceTypes>
<!-- Code package is your service executable. -->
<CodePackage Name="Code" Version="1.0.0">
<EntryPoint>
<ExeHost>
<Program>MichalBialecki.com.SF.ServiceBusExample.MessageProcessor.exe</Program>
<WorkingFolder>CodePackage</WorkingFolder>
</ExeHost>
</EntryPoint>
</CodePackage>
</ServiceManifest>
Notice that ServiceTypeName has the same value as provided when registering a service in Program class.
Next place to set-up things is ApplicationManifest.xml in SF project.
<?xml version="1.0" encoding="utf-8"?>
<ApplicationManifest xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" ApplicationTypeName="MichalBialecki.com.SF.ServiceBusExampleType" ApplicationTypeVersion="1.0.0" xmlns="http://schemas.microsoft.com/2011/01/fabric">
<Parameters>
<Parameter Name="InstanceCount" DefaultValue="1" />
</Parameters>
<!-- Import the ServiceManifest from the ServicePackage. The ServiceManifestName and ServiceManifestVersion
should match the Name and Version attributes of the ServiceManifest element defined in the
ServiceManifest.xml file. -->
<ServiceManifestImport>
<ServiceManifestRef ServiceManifestName="MichalBialecki.com.SF.ServiceBusExample.MessageProcessorPkg" ServiceManifestVersion="1.0.0" />
<ConfigOverrides />
</ServiceManifestImport>
<DefaultServices>
<!-- The section below creates instances of service types, when an instance of this
application type is created. You can also create one or more instances of service type using the
ServiceFabric PowerShell module.
The attribute ServiceTypeName below must match the name defined in the imported ServiceManifest.xml file. -->
<Service Name="MichalBialecki.com.SF.ServiceBusExample.MessageProcessor" ServicePackageActivationMode="ExclusiveProcess">
<StatelessService ServiceTypeName="MichalBialecki.com.SF.ServiceBusExample.MessageProcessorType" InstanceCount="[InstanceCount]">
<SingletonPartition />
</StatelessService>
</Service>
</DefaultServices>
</ApplicationManifest>
There are a few things you need to remember:
ServiceManifestName has the same value as ServiceManifest in ServiceManifest.xml in console app
ServiceTypeName type is the same as ServiceTypeName in ServiceManifest.xml in console app
MichalBialecki.com.SF.ServiceBusExample.MessageProcessor service has to be configured as StatelessService
Here is a proof that it really works:
That’s it, it should work. And remember that when it doesn’t, starting the whole thing again and build every small code change isn’t crazy idea 🙂
Imagine you are a Junior .Net Developer and you just started your development career. You got your first job and you are given a task – write unit tests!
Nothing to worry about, since you got me. I’ll show you how things are done and what are the best practices to follow.
Introduction
Writing unit tests is crucial to develop high-quality software and maintain it according to business requirements. Tests are the tool for developer to quickly check a small portion of code and ensure that it does what it should. In many cases tests can be unnecessary, requiring maintenance, without any gained value. However, writing tests is a standard and art that every developer should master.
Note, that writing unit tests is easy only when the code to test is written in a correct way. When methods are short, do a single thing and don’t have many dependencies, they are easy to test.
To write unit tests in this post I’ll use NUnit and NSubstitute. Those are two very popular nuget packages, that you can easily find. All code will be written in .Net Core.
Following the AAA pattern
The AAA (Arrange, Act, Assert) unit test writing pattern divides every test into 3 parts:
Arrange – in this part, you prepare data and mocks for a test scenario
Act – executing a single action that we want to test
Assert – checking whether expectations are met and mocks were triggered
Let’s have a look at a simple code, that we will test:
public class ProductNameProvider : IProductNameProvider
{
public string GetProductName(string id)
{
return "Product " + id;
}
}
And a simple test would look like this:
[TestFixture]
public class ProductNameProviderTests
{
[Test]
public void GetProductName_GivenProductId_ReturnsProductName()
{
// Arrange
var productId = "1";
var productNameProvider = new ProductNameProvider();
// Act
var result = productNameProvider.GetProductName(productId);
// Assert
Assert.AreEqual("Product " + productId, result);
}
}
This is a simple test, that checks whether the result is correct. There is a TestFixture attribute, that indicates, that this class contains a group of tests. a Test attribute marks a single test scenario.
in Arrange part we prepare productNameProvider and parameters
in Act there is only a single line where we execute GetProductName, which is a testing method
in Assert we use Assert.AreEqual to check the result. Every test needs to have at least one assertion. If any of the assertions fails, the whole test will fail
Test edge-cases
What you could see in an example above is a happy-path test. It tests only an obvious scenario. You should test code when a given parameter is not quite what you expect. The idea of that kind of tests is perfectly described in this tweet:
Let’s see an example with a REST API controller method. First, let’s see code that we would test:
[Route("api/[controller]")]
[ApiController]
public class ProductsController : ControllerBase
{
private readonly IProductService _productService;
private readonly ILogger _logger;
public ProductsController(IProductService productService, ILoggerFactory loggerFactory)
{
_productService = productService;
_logger = loggerFactory.CreateLogger(nameof(ProductsController));
}
[HttpPost]
public string Post([FromBody] ProductDto product)
{
_logger.Log(LogLevel.Information, $"Adding a products with an id {product.ProductId}");
var productGuid = _productService.SaveProduct(product);
return productGuid;
}
}
This is a standard Post method, that adds a product. There are some edge-cases though, that we should test, but first let’s see how happy-path test would look like.
[TestFixture]
public class ProductsControllerTests
{
private IProductService _productService;
private ILogger _logger;
private ProductsController _productsController;
[SetUp]
public void SetUp()
{
_productService = Substitute.For<IProductService>();
_logger = Substitute.For<ILogger>();
var loggerFactory = Substitute.For<ILoggerFactory>();
loggerFactory.CreateLogger(Arg.Any<string>()).Returns(_logger);
_productsController = new ProductsController(_productService, loggerFactory);
}
[Test]
public void Post_GivenCorrectProduct_ReturnsProductGuid()
{
// Arrange
var guid = "af95003e-b31c-4904-bfe8-c315c1d2b805";
var product = new ProductDto { ProductId = "1", ProductName = "Oven", QuantityAvailable = 3 };
_productService.SaveProduct(product).Returns(guid);
// Act
var result = _productsController.Post(product);
// Assert
Assert.AreEqual(result, guid);
_productService.Received(1).SaveProduct(product);
_logger
.Received(1)
.Log(LogLevel.Information, 0, Arg.Is<FormattedLogValues>(v => v.First().Value.ToString().Contains(product.ProductId)), Arg.Any<Exception>(), Arg.Any<Func<object, Exception, string>>());
}
}
Notice that I added:
[SetUp]
public void SetUp()
SetUp method will be run before every test and can contain code that we would need to execute for every test. In my case, it is creating mocks and setting up some mocks as well. For example, I set up a logger in order to be able to test it later. I also specify, that my ILogger mock will be returned whenever I create a logger.
In one line we both act and assert. We can also check exception fields in next checks:
[Test]
public void Post_GivenNullProduct_ThrowsNullReferenceExceptionWithMessage()
{
// Act & Assert
var exception = Assert.Throws<NullReferenceException>(() => _productsController.Post(null));
Assert.AreEqual("Object reference not set to an instance of an object.", exception.Message);
}
The important part is to set Returns values for mocks in Arrange and check mocks in Assert with Received.
Test Driven Development
To be fair with you I need to admit that this controller method ist’s written in the best way. It should be async, have parameters validation and try-catch block. We could turn our process around a bit and write tests first, that would ensure how the method should behave. This concept is called Test Driven Development – TDD. It requires from developer to write tests first and sets acceptance criteria for code that needs to be implemented.
This isn’t the easiest approach. It also expects that we know all interfaces and contracts in advance. In my opinion, it’s not useful in real-life work, maybe with one exception. The only scenario I’d like to have tests first would be a refactoring of an old code, where we write one part of it anew. In this scenario, I would copy or write tests to ensure that new code works exactly the same as the old one.
Naming things
Important thing is to follow patterns that are visible in your project and stick to it. Naming things correctly might sound obvious and silly, but it’s crucial for code organization and it’s visibility.
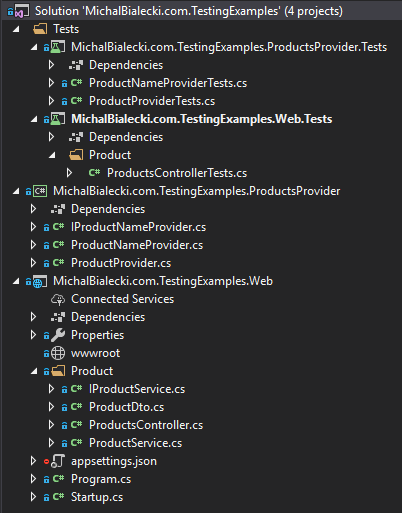
First, let’s have a look at the project structure. Notice that all test projects are in Tests directory and names of those projects are same as projects they test plus “Tests”. Directories that tests are in are corresponding to those that we test, so that directory structure in both projects is the same. Test classes names are also the same.
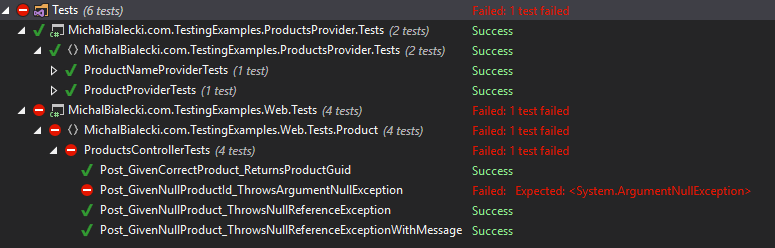
Next thing is naming test scenarios. Have a look test results in Resharper window:
In this project, every class has its corresponding test class. Each test scenario is named in such pattern: [method name]_[input]_[expected result]. Only looking at the test structure I already know what method is tested and what this test scenario is about. Remember that the test scenario should be small and should test a separate thing if that’s possible. It doesn’t mean that when you test a mapper, you should have a separate scenario for every property mapped, but you might consider dividing those tests to have: happy-path test and all the edge cases.
That’s it! You are ready for work, so go and write your own tests:)
You can play with a code a bit, write more classes and tests. If you like this topic or you’d like to have some practical test assignment prepared to test yourself, please let me know:)
I recently was developing a console application in .net core, where I had to use log4net logging.
In the standard asp.net core approach we can use:
public void Configure(IApplicationBuilder app, Microsoft.Extensions.Logging.ILoggerFactory loggerFactory)
{
loggerFactory.AddLog4Net();
}
But this is .net core console application, where I’m creating LoggerFactory on my own, so it would not work.
In order to solve it, I had to implement my own Log4NetProvider, that would implement ILoggerProvider.
public class Log4NetProvider : ILoggerProvider
{
private readonly string _log4NetConfigFile;
private readonly bool _skipDiagnosticLogs;
private readonly ConcurrentDictionary<string, ILogger> _loggers =
new ConcurrentDictionary<string, ILogger>();
public Log4NetProvider(string log4NetConfigFile, bool skipDiagnosticLogs)
{
_log4NetConfigFile = log4NetConfigFile;
_skipDiagnosticLogs = skipDiagnosticLogs;
}
public ILogger CreateLogger(string categoryName)
{
return _loggers.GetOrAdd(categoryName, CreateLoggerImplementation);
}
public void Dispose()
{
_loggers.Clear();
}
private ILogger CreateLoggerImplementation(string name)
{
return new Log4NetLogger(name, new FileInfo(_log4NetConfigFile), _skipDiagnosticLogs);
}
}
And the implementation of an actual logger:
public class Log4NetLogger : ILogger
{
private readonly string _name;
private readonly ILog _log;
private readonly bool _skipDiagnosticLogs;
private ILoggerRepository _loggerRepository;
public Log4NetLogger(string name, FileInfo fileInfo, bool skipDiagnosticLogs)
{
_name = name;
_loggerRepository = LogManager.GetRepository(Assembly.GetEntryAssembly());
_log = LogManager.GetLogger(_loggerRepository.Name, name);
_skipDiagnosticLogs = skipDiagnosticLogs;
log4net.Config.XmlConfigurator.Configure(_loggerRepository, fileInfo);
}
public IDisposable BeginScope<TState>(TState state)
{
return null;
}
public bool IsEnabled(LogLevel logLevel)
{
switch (logLevel)
{
case LogLevel.Critical:
return _log.IsFatalEnabled;
case LogLevel.Debug:
case LogLevel.Trace:
return _log.IsDebugEnabled && AllowDiagnostics();
case LogLevel.Error:
return _log.IsErrorEnabled;
case LogLevel.Information:
return _log.IsInfoEnabled && AllowDiagnostics();
case LogLevel.Warning:
return _log.IsWarnEnabled;
default:
throw new ArgumentOutOfRangeException(nameof(logLevel));
}
}
public void Log<TState>(
LogLevel logLevel,
EventId eventId,
TState state,
Exception exception,
Func<TState, Exception, string> formatter)
{
if (!IsEnabled(logLevel))
{
return;
}
if (formatter == null)
{
throw new ArgumentNullException(nameof(formatter));
}
string message = $"{formatter(state, exception)} {exception}";
if (!string.IsNullOrEmpty(message) || exception != null)
{
switch (logLevel)
{
case LogLevel.Critical:
_log.Fatal(message);
break;
case LogLevel.Debug:
case LogLevel.Trace:
_log.Debug(message);
break;
case LogLevel.Error:
_log.Error(message);
break;
case LogLevel.Information:
_log.Info(message);
break;
case LogLevel.Warning:
_log.Warn(message);
break;
default:
_log.Warn($"Encountered unknown log level {logLevel}, writing out as Info.");
_log.Info(message, exception);
break;
}
}
}
private bool AllowDiagnostics()
{
if (!_skipDiagnosticLogs)
{
return true;
}
return !(_name.ToLower().StartsWith("microsoft")
|| _name == "IdentityServer4.AccessTokenValidation.Infrastructure.NopAuthenticationMiddleware");
}
}
One last touch is adding an extension for ILoggerFactory to be able to use AddLog4Net.
public static class Log4netExtensions
{
public static ILoggerFactory AddLog4Net(this ILoggerFactory factory, bool skipDiagnosticLogs)
{
factory.AddProvider(new Log4NetProvider("log4net.config", skipDiagnosticLogs));
return factory;
}
}
In my DI container registration, I added code:
var loggerFactory = new Microsoft.Extensions.Logging.LoggerFactory();
loggerFactory.AddLog4Net(true);
Container.RegisterInstance<Microsoft.Extensions.Logging.ILoggerFactory>(loggerFactory);
Recently I’m diving into Microsoft actor model implementation – Service Fabric Reliable Actors. Apart from Microsoft Orleans, is another one worth looking into. Let’s start from the beginning.
What is Service Fabric? It is many things and can be compared to Kubernetes:
Simplify microservices development and application lifecycle management
Reliably scale and orchestrate containers and microservices
Data-aware platform for low-latency, high-throughput workloads with stateful containers or microservices
Run anything – your choice of languages and programming models
Run anywhere – supports Windows/Linux in Azure, on-premises, or other clouds
From my perspective, it is just another way to manage micro-services. It can be set up on Azure or on-premise. Its biggest disadvantage is it’s dashboard, that does not offer much, comparing to IIS or Azure.
What are Reliable Actors? It is a Service Fabric implementation of an actor pattern, that is great for handling many small parallel operations. Actor, in this case, is a small piece of business logic, that can hold state and all actors can work simultaneously and independently, no matter if there is a hundred or hundred thousand of them.
If you’re new to actor model, you can have a look at an introduction to Microsoft Orleans. It covers all the basics: Getting started with Microsoft Orleans
Scenario
Let’s have an example to understand how all of this can be used in practice.
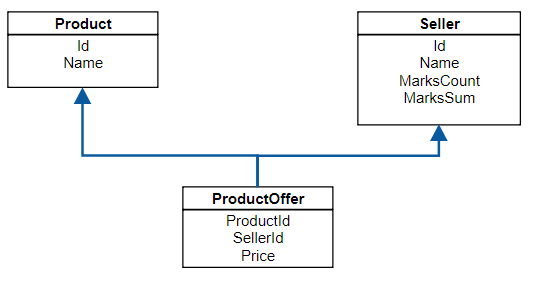
Let’s build price comparer micro-service, that will maintain sellers, products and offers for products. Every seller can have many offers for many products and every product will have many offers from many sellers. Something that in DB will look like this:
The main features of this service are:
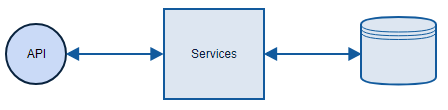
it is a REST micro-service, so all communication will go through it’s API
it needs to persist its state
when getting a product, it needs to respond with json, where offers are sorted by seller rating descending
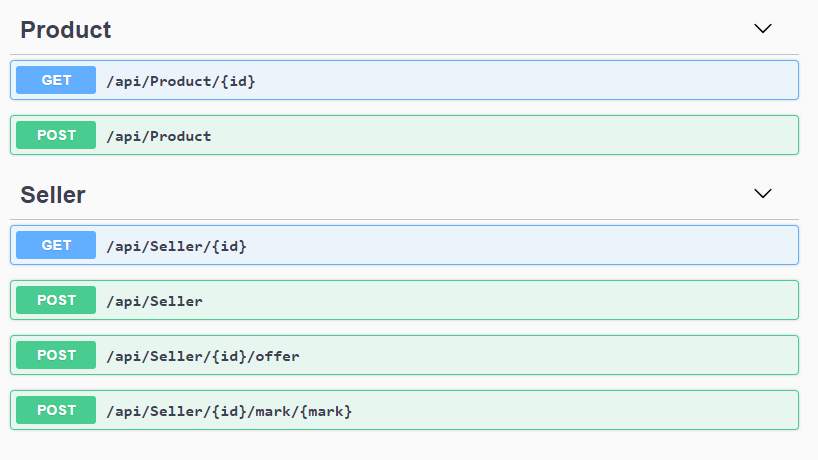
The last requirement forces us to update product offers whenever seller rating changes. Whenever seller rating changes, all its product offers need to be reordered. It sounds complicated, but it’s easier than it seems. API looks like this:
And Json that we would like to get in return, looks like this:
Simple micro-service approach
I already showed you how DB model can look like and this is precisely the way I’m going to implement it. Every operation will go to DB and take data from there. The architecture will be simple:
Of course I might keep my state in memory and update it whenever something changes, but this is rather difficult. In fact, cache invalidation is told to be one of the two hardest problems in software development. Right after naming things.
Let’s have a look how SellerController is built, it’s rather simple:
public class SellerRepository : ISellerRepository
{
private const string RemoveSeller = @"DELETE FROM Seller WHERE Id = @Id";
private const string InsertSeller = @"INSERT INTO Seller (Id, Name, MarksCount, MarksSum) VALUES (@Id, @Name, @MarksCount, @MarksSum)";
private const string UpdateSellerRating = @"UPDATE Seller SET MarksCount = @MarksCount, MarksSum = @MarksSum WHERE Id = @Id";
private const string GetSeller = @"SELECT Id, Name, MarksCount, MarksSum FROM Seller WHERE Id = @id";
private const string GetSellerOffers = @"SELECT ProductId, Price FROM ProductOffer WHERE SellerId = @id";
private readonly IConfigurationRoot _configuration;
public SellerRepository(IConfigurationRoot configuration)
{
_configuration = configuration;
}
public async Task Save(Seller seller)
{
using (var connection = new SqlConnection(_configuration.GetConnectionString("DbConnectionString")))
{
await connection.ExecuteAsync(RemoveSeller, new { seller.Id });
await connection.ExecuteAsync(InsertSeller, seller);
}
}
public async Task<Seller> Get(string id)
{
using (var connection = new SqlConnection(_configuration.GetConnectionString("DbConnectionString")))
{
var sellerOffers = await connection.QueryAsync<Offer>(GetSellerOffers, new { id });
var seller = await connection.QuerySingleAsync<Seller>(GetSeller, new { id });
seller.Offers = sellerOffers.ToList();
return seller;
}
}
public async Task Update(Seller seller)
{
using (var connection = new SqlConnection(_configuration.GetConnectionString("DbConnectionString")))
{
await connection.ExecuteAsync(UpdateSellerRating, seller);
}
}
}
To be able to use code like this:
connection.QuerySingleAsync<Seller>(GetSeller, new { id })
I used Dapper nuget package – very handy tool that enriches simple IDbConnection with new features.
Service Fabric approach
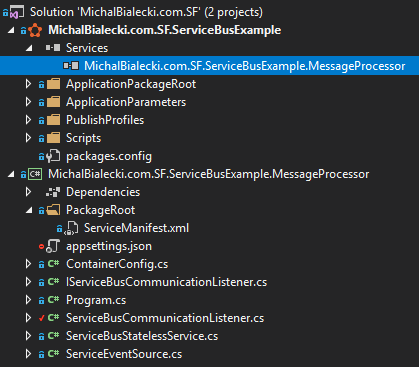
The functionality of Service Fabric implementation will be exactly the same. Small micro-service that exposes REST API and ensures that state is persistent. And this is where similarities end. First, let’s have a look at the project structure:
From the top:
MichalBialecki.com.SF.PriceComparer – have you noticed Service Fabric icon? It contains configuration how to set up SF cluster and what application should be hosted. It also defines how they will be scaled
PriceComparer – Business logic for API project, it contains actor implementation
PriceComparer.Api – REST API that we expose. Notice that we also have ServiceManifest.xml that is a definition of our service in Service Fabric
PriceComparer.Interfaces – the name speaks for itself, just interfaces and dtos
Controller implementation is almost the same as in the previous approach. Instead of using repository it uses actors.
ActorProxy.Create<ISellerActor> is the way we instantiate an actor, it is provided by the framework. Implementation of SellerActor needs to inherit Actor class. It also defines on top of the class how the state will be maintained. In our case it will be persisted, that means it will be saved as a file on a disk on the machine where the cluster is located.
[StatePersistence(StatePersistence.Persisted)]
internal class SellerActor : Actor, ISellerActor
{
private const string StateName = nameof(SellerActor);
public SellerActor(ActorService actorService, ActorId actorId)
: base(actorService, actorId)
{
}
public async Task AddSeller(Seller seller, CancellationToken cancellationToken)
{
await StateManager.AddOrUpdateStateAsync(StateName, seller, (key, value) => value, cancellationToken);
}
public async Task<Seller> GetState(CancellationToken cancellationToken)
{
return await StateManager.GetOrAddStateAsync(StateName, new Seller(), cancellationToken);
}
public async Task AddOffer(Offer offer, CancellationToken cancellationToken)
{
var seller = await StateManager.GetOrAddStateAsync(StateName, new Seller(), cancellationToken);
var existingOffer = seller.Offers.FirstOrDefault(o => o.ProductId == offer.ProductId);
if (existingOffer != null)
{
seller.Offers.Remove(existingOffer);
}
seller.Offers.Add(offer);
var sellerOffer = new SellerOffer
{
ProductId = offer.ProductId,
Price = offer.Price,
SellerId = seller.Id,
SellerRating = seller.Rating,
SellerName = seller.Name
};
var productActor = ActorProxy.Create<IProductActor>(new ActorId(offer.ProductId));
await productActor.UpdateSellerOffer(sellerOffer, cancellationToken);
await StateManager.SetStateAsync(StateName, seller, cancellationToken);
}
public async Task Mark(decimal value, CancellationToken cancellationToken)
{
var seller = await StateManager.GetOrAddStateAsync(StateName, new Seller(), cancellationToken);
seller.MarksCount += 1;
seller.MarksSum += value;
await StateManager.SetStateAsync(StateName, seller, cancellationToken);
foreach (var offer in seller.Offers)
{
var productActor = ActorProxy.Create<IProductActor>(new ActorId(offer.ProductId));
await productActor.UpdateSellerRating(seller.Id, seller.Rating, cancellationToken);
}
}
}
Notice that in order to use state, we use StateManager, also provided by the framework. The safest way is to either user GetOrAddStateAsync or SetStateAsync. Fun fact – all methods are asynchronous, there are no sync ones. There is a good emphasis on making code async, so that it can be run better in parallel with other jobs.
Take a look at Mark method. In order to mark a seller, we need to get its state, increment counters and save state. Then we need to update all product offers that seller has. Let’s take a look at how updating product looks like:
public async Task UpdateSellerRating(string sellerId, decimal sellerRating, CancellationToken cancellationToken)
{
var product = await StateManager.GetOrAddStateAsync(StateName, new Product(), cancellationToken);
var existingMatchingOffer = product.Offers.FirstOrDefault(o => o.SellerId == sellerId);
if (existingMatchingOffer != null)
{
existingMatchingOffer.SellerRating = sellerRating;
product.Offers = product.Offers.OrderByDescending(o => o.SellerRating).ToList();
await StateManager.SetStateAsync(StateName, product, cancellationToken);
}
}
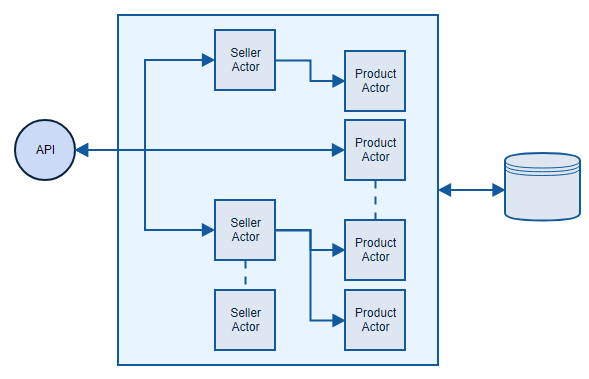
We are updating seller rating in his offer inside a product. That can happen for thousands of products, but since this job is done in different actors, it can be done in parallel. Architecture for this approach is way different when compared to simple micro-service.
Comparison
To compare both approaches I assumed I need a lot of data, so I prepared:
1000 sellers having
10000 products with
100000 offers combined
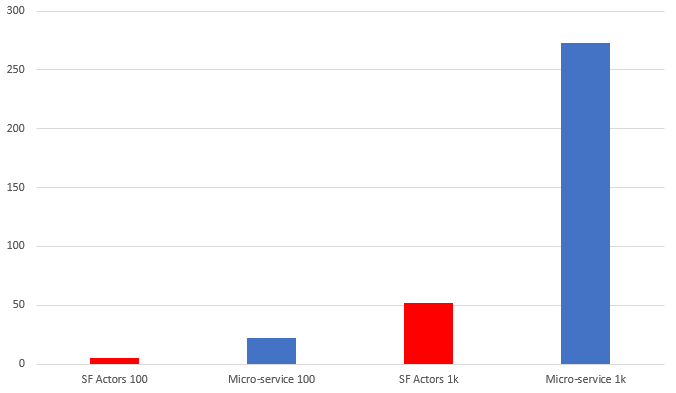
It sounds a lot, but in a real-life price comparer, this could be just a start. A good starting point for my test, though. The first thing that hit me was loading this data into both services. Since both approaches exposed the same API, I just needed to make 11000 requests to initialize everything. With Service Fabric it all went well, after around 1 minute everything was initialized. However with simple DB approach… it throws SQL timeout exceptions. It turned out, that it couldn’t handle so many requests, even when I extended DB connection timeout. I needed to implement batch init, and after a few tries, I did it. However, the time that I needed to initialize all the data wasn’t so optimistic.
First two columns stand for initializing everything divided by 10, and second two stands for full initialization. Notice that a simple DB approach took around 5 times more than Service Fabric implementation!
To test the performance of my services I needed to send a lot of requests at the same time. In order to do that I used Locust – a performance load tool. It can be easily installed and set up. After preparing a small file that represents a testing scenario, I just run it from the terminal and then I can go to its dashboard, that is accessible via a browser.
Let’s have a look at how the performance of the first approach looks like. In this case, Locust will simulate 200 users, that grows from 0 to 200, 20 users per second. It will handle around 30 requests per second with an average response time 40 ms. When I update that value to 400 users, it will handle around 50 requests per minute, but response time will go to around 3 seconds. That, of course, is not acceptable in micro-service development.
The second video shows the same test, but hitting Service Fabric app. This time I’d like to go bold and start off with 1000 users. It will handle around 140 RPM with an average response time around 30ms, which is even faster than 400 users and first approach. Then I’ll try 2000 users, have a look:
Summary
I showed you two approaches, both written in .Net Core 2.0. The first one is a very simple one using SQL DB, and the second one is Service Fabric with Reliable Actors. From my tests, I could easily see that actors approach is way more performant. Probably around 5 times in this specific case. Let’s point this out:
Pros:
very fast in scenarios, where there are many small pieces of business logic, tightly connected to data
trivial to try and implement – there is a Visual Studio project for that
Cons:
It’s more complicated to implement than the regular approach
Configuring Service Fabric with XML files can be frustrating
Since everything handled by the framework, a developer has a bit less control over what’s happening
Microsoft Orleans is a developer-friendly framework for building distributed, high-scale computing applications. It does not require from developer to implement concurrency and data storage model. It requires developer to use predefined code blocks and enforces application to be build in a certain way. As a result Microsoft Orleans empowers developer with a framework with an exceptional performance.
Orleans proved its strengths in many scenarios, where the most recognizable ones are cloud services for Halo 4 and 5 games.
To test the performance of Microsoft Orleans I’ll compare it to simple micro-service implementation. The scenario is about transferring money from one account to another using a persistent storage. Here is the idea:
Both services will use .Net Core
Data will be saved in Azure CosmosDB database
Services will read and send messages from Service Bus
One message will trigger transferring money, that will need to get and save data from DB and then service will send two messages with account balance updates
Simple Micro-service approach
This app is really simple. It is a console application, that registers message handler and processes messages. This is how architecture looks like, simple right?
Code that handles message looks like this:
public void Run()
{
var service = new TableStorageService(_configuration);
try
{
var subscriptionClient = new SubscriptionClient(
_configuration[ServiceBusKey],
"accountTransferUpdates",
"commonSubscription");
subscriptionClient.PrefetchCount = 1000;
subscriptionClient.RegisterMessageHandler(
async (message, token) =>
{
var messageJson = Encoding.UTF8.GetString(message.Body);
var updateMessage = JsonConvert.DeserializeObject<AccountTransferMessage>(messageJson);
await service.UpdateAccount(updateMessage.From, -updateMessage.Amount);
await service.UpdateAccount(updateMessage.To, updateMessage.Amount);
Console.WriteLine($"Processed a message from {updateMessage.From} to {updateMessage.To}");
},
new MessageHandlerOptions(OnException)
{
MaxAutoRenewDuration = TimeSpan.FromMinutes(60),
MaxConcurrentCalls = 1,
AutoComplete = true
});
}
catch (Exception e)
{
Console.WriteLine("Exception: " + e.Message);
}
}
private Task OnException(ExceptionReceivedEventArgs args)
{
Console.WriteLine(args.Exception);
return Task.CompletedTask;
}
TableStorageService is used to synchronize state with the database, which in this case it read and update account balance.
public class TableStorageService
{
private const string EndpointUriKey = "CosmosDbEndpointUri";
private const string PrimaryKeyKey = "CosmosDbPrimaryKey";
private const string ServiceBusKey = "ServiceBusConnectionString";
private readonly DocumentClient client;
private readonly TopicClient topic;
public TableStorageService(IConfigurationRoot configuration)
{
client = new DocumentClient(new Uri(configuration[EndpointUriKey]), configuration[PrimaryKeyKey]);
topic = new TopicClient(configuration[ServiceBusKey], "balanceUpdates");
}
public async Task UpdateAccount(int accountNumber, decimal amount)
{
Account document;
try
{
var response = await client.ReadDocumentAsync<Account>(accountNumber.ToString());
document = response.Document;
document.Balance += amount;
await client.ReplaceDocumentAsync(accountNumber.ToString(), document);
}
catch (DocumentClientException de)
{
if (de.StatusCode == HttpStatusCode.NotFound)
{
document = new Account { Id = accountNumber.ToString(), Balance = amount };
await client.CreateDocumentAsync(UriFactory.CreateDocumentCollectionUri("bialecki", "accounts"), document);
}
else
{
throw;
}
}
await NotifyBalanceUpdate(accountNumber, document.Balance);
}
private async Task NotifyBalanceUpdate(int accountNumber, decimal balance)
{
var balanceUpdate = new BalanceUpdateMessage
{
AccountNumber = accountNumber,
Balance = balance
};
var message = new Message(Encoding.UTF8.GetBytes(JsonConvert.SerializeObject(balanceUpdate)));
await topic.SendAsync(message);
}
}
DocumentClient is CosmosDB client provided by the framework. You might be intrigued by try-catch clause. Currently for in CosmosDB package for .Net Core there is no way to check if the document exists and the proposed solution is to handle an exception when the document is not found. In this case, the new document will be created. NotifyBalanceUpdate sends messages to Service Bus.
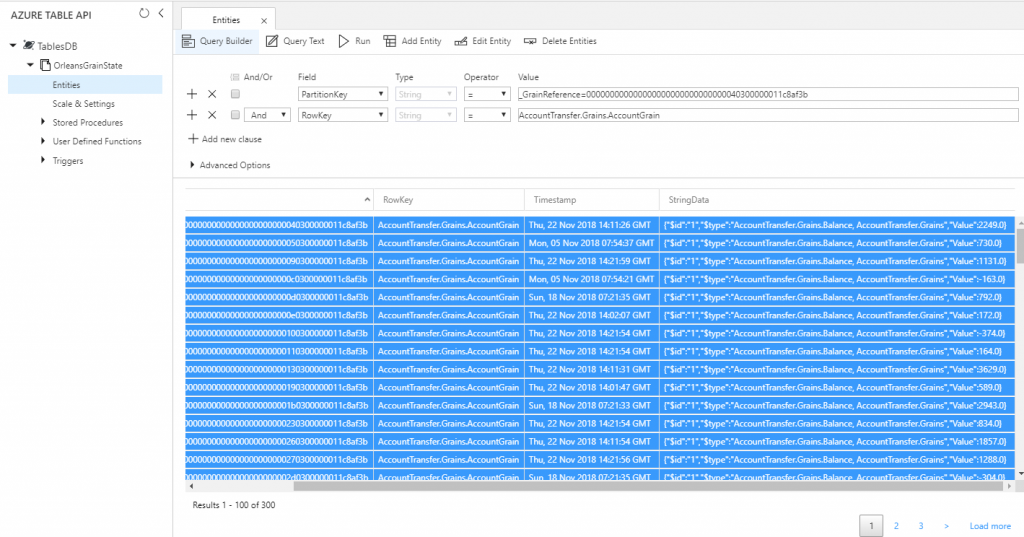
When we go to Azure portal, we can query the data to check if it is really there:
This is how reading 100 messages looks like:
Microsoft Orleans approach
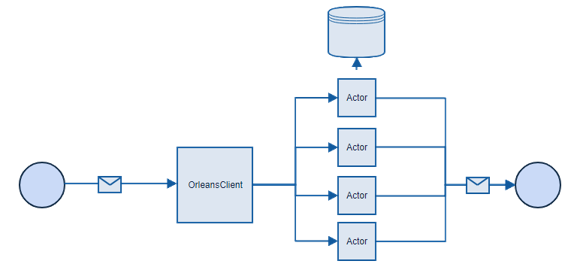
Microsoft Orleans is an actor framework, where each actor can be understood as a separate service, that does some simple operations and can have its own state. In this case, every account can be an actor, it doesn’t matter if we have few or few hundred thousands of them, the framework will handle that. Another big advantage is that we do not need to care about concurrency and persistence, it is also handled by the framework for us. In Orleans, accounts can perform operations in parallel. In this case, the architecture looks much different.
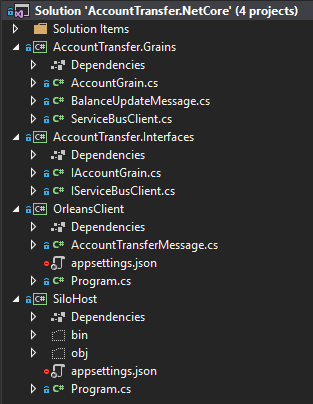
Project structure looks like this:
SiloHost – sets up and run a silo to host grains, which is just another name for actors
OrleansClient – second application. This one connects to the silo and run client code to use grains
AccountTransfer.Interfaces – its an abstraction for grains
AccountTransfer.Grains – grains implementation, that handles business logic
Let’s have a look at how running a silo looks like:
public class Program
{
private static IConfigurationRoot configuration;
public static int Main(string[] args)
{
return RunMainAsync().Result;
}
private static async Task<int> RunMainAsync()
{
try
{
var builder = new ConfigurationBuilder()
.SetBasePath(Directory.GetCurrentDirectory())
.AddJsonFile("appsettings.json", optional: true, reloadOnChange: true);
configuration = builder.Build();
var host = await StartSilo();
Console.WriteLine("Press Enter to terminate...");
Console.ReadLine();
await host.StopAsync();
return 0;
}
catch (Exception ex)
{
Console.WriteLine(ex);
return 1;
}
}
private static async Task<ISiloHost> StartSilo()
{
var builder = new SiloHostBuilder()
.UseLocalhostClustering()
.Configure<EndpointOptions>(options => options.AdvertisedIPAddress = IPAddress.Loopback)
.ConfigureServices(context => ConfigureDI(context))
.ConfigureLogging(logging => logging.AddConsole())
.UseInClusterTransactionManager()
.UseInMemoryTransactionLog()
.AddAzureTableGrainStorageAsDefault(
(options) =>
{
options.ConnectionString = configuration.GetConnectionString("CosmosBDConnectionString");
options.UseJson = true;
})
.UseTransactionalState();
var host = builder.Build();
await host.StartAsync();
return host;
}
private static IServiceProvider ConfigureDI(IServiceCollection services)
{
services.AddSingleton<IServiceBusClient>((sp) => new ServiceBusClient(configuration.GetConnectionString("ServiceBusConnectionString")));
return services.BuildServiceProvider();
}
}
This is the whole code. Amazingly short comparing to what we are doing here. Notice, that configuring CosmosDB Azure Table storage takes just a few lines. I even configured dependency injection that I will use in account grain.
This is also a simple console application. Both apps need to be run together, cause client is connecting to the silo and if fails, tries again after few seconds. The only part missing here is DoClientWork method:
private static void DoClientWork(IClusterClient client)
{
var subscriptionClient = new SubscriptionClient(
configuration.GetConnectionString("ServiceBusConnectionString"),
"accountTransferUpdates",
"orleansSubscription",
ReceiveMode.ReceiveAndDelete);
subscriptionClient.PrefetchCount = 1000;
try
{
subscriptionClient.RegisterMessageHandler(
async (message, token) =>
{
var messageJson = Encoding.UTF8.GetString(message.Body);
var updateMessage = JsonConvert.DeserializeObject<AccountTransferMessage>(messageJson);
await client.GetGrain<IAccountGrain>(updateMessage.From).Withdraw(updateMessage.Amount);
await client.GetGrain<IAccountGrain>(updateMessage.To).Deposit(updateMessage.Amount);
Console.WriteLine($"Processed a message from {updateMessage.From} to {updateMessage.To}");
await Task.CompletedTask;
},
new MessageHandlerOptions(HandleException)
{
MaxAutoRenewDuration = TimeSpan.FromMinutes(60),
MaxConcurrentCalls = 20,
AutoComplete = true
});
}
catch (Exception e)
{
Console.WriteLine("Exception: " + e.Message);
}
}
This is almost the same code that we had in micro-service approach. We are reading Service Bus messages and deserialize them, but then we use actors. From this point execution will be handled by them. AccountGrain looks like this:
[Serializable]
public class Balance
{
public decimal Value { get; set; } = 1000;
}
public class AccountGrain : Grain<Balance>, IAccountGrain
{
private readonly IServiceBusClient serviceBusClient;
public AccountGrain(
IServiceBusClient serviceBusClient)
{
this.serviceBusClient = serviceBusClient;
}
async Task IAccountGrain.Deposit(decimal amount)
{
try
{
this.State.Value += amount;
await this.WriteStateAsync();
await NotifyBalanceUpdate();
}
catch (Exception e)
{
Console.WriteLine(e);
}
}
async Task IAccountGrain.Withdraw(decimal amount)
{
this.State.Value -= amount;
await this.WriteStateAsync();
await NotifyBalanceUpdate();
}
Task<decimal> IAccountGrain.GetBalance()
{
return Task.FromResult(this.State.Value);
}
private async Task NotifyBalanceUpdate()
{
var balanceUpdate = new BalanceUpdateMessage
{
AccountNumber = (int)this.GetPrimaryKeyLong(),
Balance = this.State.Value
};
var message = new Message(Encoding.UTF8.GetBytes(JsonConvert.SerializeObject(balanceUpdate)));
await serviceBusClient.SendMessageAsync(message);
}
}
Notice that on top we have serializable Balance class. When defining actor like this: AccountGrain : Grain<Balance>, it means that Balance will be our state, that we can later refer to as this.State. Getting and updating state is trivial, and both Withdraw and Deposit causes sending Service Bus message by calling NotifyBalanceUpdate.
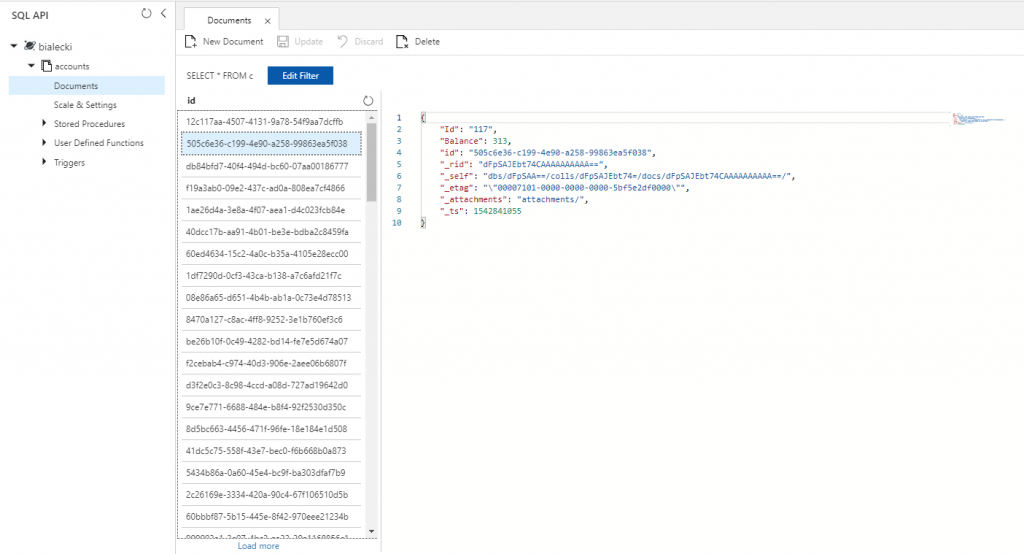
In Azure portal we can have a look how data is saved. I choose to serialize it to json, so we can see account state easily:
Let’s have a look at reading 1000 messages by a single thread with Microsoft Orleans looks like:
It runs noticeably faster, but what’s more interesting is that we can read messages with even 20 concurrent threads at a time:
Comparsion
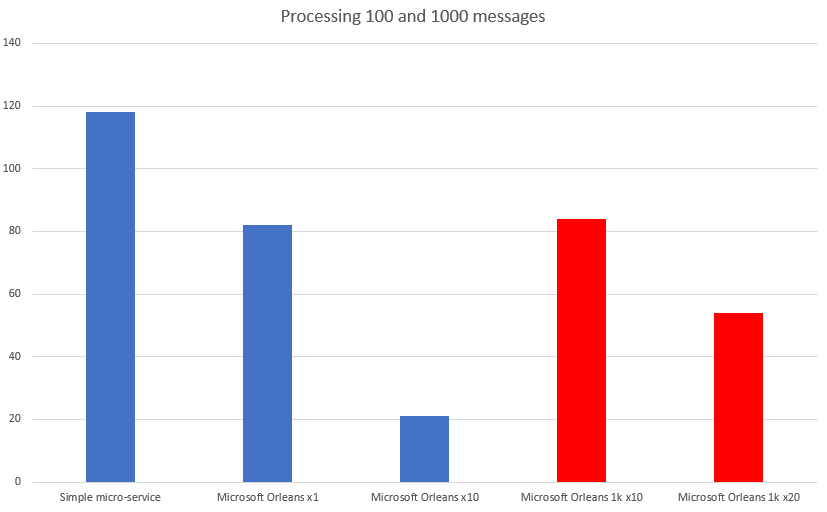
As you could see, I used two approaches to read and process 100 and 1000 Service Bus messages, written in .net core with a persistant state in remote CosmosDB database. Results can be seen here:
Blue color represents reading 100 messages, red represents reading 1000 messages. As you can see Microsoft Orleans is a few times faster.
To sum up, using Microsoft Orleans:
Pros:
Microsoft actor framework could give you outstanding performance
It requires minimal knowledge to write your first app
Documentation is great
The code is open source, you can post issues
Cons:
It doesn’t fit every scenario
Maintenance and deployment is a bit more difficult than a simple IIS app
If you’re interested in the code, have a look at my GitHub:
From version 3.1 of Microsoft.Azure.ServiceBus it is finally possible to manage queues, topics and subscriptions in .Net Core. Let’s have a look at how we can use it in real life scenarios.
Previously we would use sample code for getting a queue:
public IQueueClient GetQueueClient(string _serviceBusConnectionString, string _queueName)
{
var queueClient = new QueueClient(_serviceBusConnectionString, _queueName);
return queueClient;
}
Using ManagementClient we can write much better code.
public async Task<IQueueClient> GetOrCreateQueue(string _serviceBusConnectionString, string _queueName)
{
var managementClient = new ManagementClient(_serviceBusConnectionString);
if (!(await managementClient.QueueExistsAsync(_queueName)))
{
await managementClient.CreateQueueAsync(new QueueDescription(_queueName));
}
var queueClient = new QueueClient(_serviceBusConnectionString, _queueName);
return queueClient;
}
Now before getting a queue, we are checking if a queue exists and if not, we are creating it. So when executing this code:
It is pretty easy to create a topic subscription or a queue, but SubscriptionDescription object offers a lot more then just that. This is a simple code that creates a subscription:
public async Task<ISubscriptionClient> GetOrCreateTopicSubscription(string serviceBusConnectionString, string topicPath, string subscriptionName)
{
var managementClient = new ManagementClient(serviceBusConnectionString);
if (!(await managementClient.SubscriptionExistsAsync(topicPath, subscriptionName)))
{
await managementClient.CreateSubscriptionAsync(new SubscriptionDescription(topicPath, subscriptionName));
}
var subscriptionClient = new SubscriptionClient(serviceBusConnectionString, topicPath, subscriptionName);
return subscriptionClient;
}
Let’s have a look at a few most important properties:
This is the duration after which the message expires, starting from when the message is sent to the Service Bus. After that time, the message will be removed from a subscription
EnableDeadLetteringOnMessageExpiration
Support for dead-letter queue. When you enable it, messages will come here instead of being removed from the main queue
Maximum count of message returning to the subscription after failure processing. After that count message will be removed from the subscription
Let’s have a look what we can fill in in a real project.
public async Task<ISubscriptionClient> GetOrCreateTopicSubscription(string serviceBusConnectionString, string topicPath, string subscriptionName)
{
var managementClient = new ManagementClient(serviceBusConnectionString);
if (!(await managementClient.SubscriptionExistsAsync(topicPath, subscriptionName)))
{
await managementClient.CreateSubscriptionAsync(
new SubscriptionDescription(topicPath, subscriptionName)
{
EnableBatchedOperations = true,
AutoDeleteOnIdle = System.TimeSpan.FromDays(100),
EnableDeadLetteringOnMessageExpiration = true,
DefaultMessageTimeToLive = System.TimeSpan.FromDays(100),
MaxDeliveryCount = 100,
LockDuration = System.TimeSpan.FromMinutes(5)
});
}
var subscriptionClient = new SubscriptionClient(serviceBusConnectionString, topicPath, subscriptionName);
return subscriptionClient;
}
AutoDeleteOnIdle – subscription will be removed from the topic after 100 days idle – that is very unlikely. DefaultMessageTimeToLive and EnableDeadLetteringOnMessageExpiration – messages will be kept in the queue for very long – 100 days, then they will be sent to a dead letter queue. MaxDeliveryCount and LockDuration – message will be processed up to 100 times and for a maximum of 5 minutes.
We can do one more thing. When testing a project while development locally it’s ideal to work with real data. In the real case, we would probably have different Service Bus namespace and separate connection string for every environment. There is, however, a trick to use DEV data locally – just create your testing subscription! This is how it can look like:
Testing subscription will have it’s own name, it will still be there up to 100 days of idle, but messages will be kept only for 2 days and they will not end up in dead letter queue. MaxDeliveryCount is only 5, cause if something goes wrong, we will end up having 5 the same errors in logs instead of 100 and this is much more likely to happen when testing locally.









 I need to admit, that I got an NDepend license for free to test it out. If it wasn’t for Patrick Smacchia from NDepend, I wouldn’t discover that anytime soon. And I would never learn, that no matter how good you get in your work, you always can do better.
I need to admit, that I got an NDepend license for free to test it out. If it wasn’t for Patrick Smacchia from NDepend, I wouldn’t discover that anytime soon. And I would never learn, that no matter how good you get in your work, you always can do better.


 Imagine you are a Junior .Net Developer and you just started your development career. You got your first job and you are given a task – write unit tests!
Imagine you are a Junior .Net Developer and you just started your development career. You got your first job and you are given a task – write unit tests!
 Important thing is to follow patterns that are visible in your project and stick to it. Naming things correctly might sound obvious and silly, but it’s crucial for code organization and it’s visibility.
Important thing is to follow patterns that are visible in your project and stick to it. Naming things correctly might sound obvious and silly, but it’s crucial for code organization and it’s visibility.