Entity Framework Core 5 to lekki i łatwy w użyciu ORM, który pozwala korzystać z bazy danych bez pisania jakichkolwiek poleceń SQL. Wbudowane mechanizmy będą tłumaczyć zapytania LINQ dotyczące klas encji na zapytania SQL i zwracać zamapowane obiekty.
Zerknij też na post dotyczący dodawania EF Core z migracjami do pustej bazy danych: PrimeHotel – dodanie Entity Framework Core 5 w .NET 5
Dodanie Entity Framework Core 5 jest bardzo proste, jeśli masz pustą bazę danych, ale czy jest to takie łatwe podczas pracy z bazą danych, która posiada już swoją strukturę? Czy musimy to wszystko mapować, czy możemy po prostu pracować z częścią bazy danych, która nas interesuje? Zacznijmy od początku.
Czego potrzebujemy
Aby pracować z EF Core 5, musimy zainstalować pakiety NuGet:
- Microsoft.EntityFrameworkCore
- Microsoft.EntityFrameworkCore.Design
- Microsoft.EntityFrameworkCore.SqlServer
Ostatni pakiet zdradza nam, że będziemy pracować z bazą danych MS SQL Server. Teraz połączmy się z naszą bazą danych i zobaczmy, jak to wygląda.
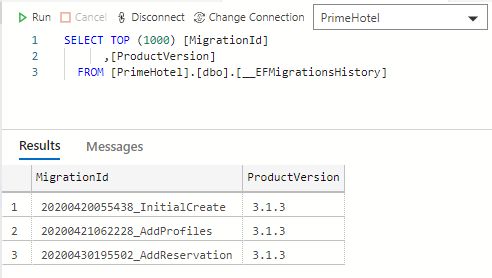
Do pracy z bazą danych używam Azure Data Studio, które jest lekkim i szybkim narzędziem, które może wykonywać większość podstawowych operacji na bazach danych. Jest znacznie szybszy niż SQL Server Management Studio i do większości mojej pracy używam właśnie tego pierwszego.
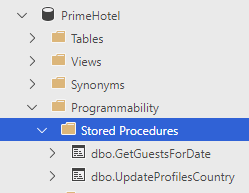
Dodamy EF Core dla bazy danych aspnetcore, która wygląda następująco.
Dodanie klasy DbContext
Następną rzeczą, którą musimy zrobić, jest utworzenie klasy DbContext. Moglibyśmy stworzyć ją ręcznie i wszystko wpisać ręcznie. Jednak .NET Core ma narzędzia do tworzenia i generowania ich automatycznie.
Proces ten nazywa się inżynierią wsteczną i jest to tworzenie szkieletów klas encji i klasy DbContext w oparciu o schemat bazy danych. Aby wykonać tę operację, użyjemy narzędzia .NET CLI, które musisz zainstalować, jeśli jeszcze tego nie zrobiłeś. Wpisz poniższe polecenie, aby to sprawdzić:
dotnet tool install --global dotnet-ef
Możesz także zaktualizować narzędzie po jego zainstalowaniu:

Proces tworzenia szkieletu wymaga connection stringa do przekazania. Moglibyśmy go przekazać w poleceniu, ale możemy też wykonać to zadanie w bardziej elegancki sposób, podając tylko jego nazwę.
Przejdźmy do pliku appsettings.json i skonfigurujmy connection string dla naszej nowej bazy danych.
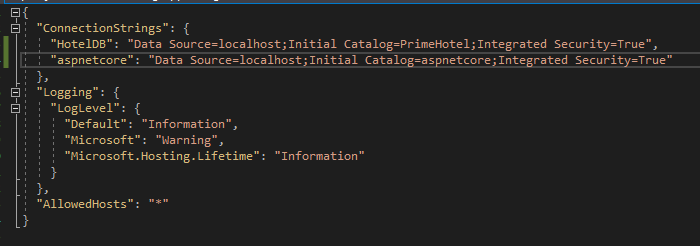
Dodałem connection string o nazwie aspnetcore w sekcji ConnectionStrings.
Polecenie, którego będziemy używać, jest bardzo proste, uruchom je w katalogu swojego projektu:
dotnet ef dbcontext scaffold Name=aspnetcore Microsoft.EntityFrameworkCore.SqlServer
Powyższe polecenie doda aspnetcoreDbContext i wszystkie encje reprezentujące bazę danych.
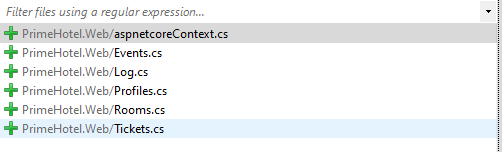
Efekt jest zadowalający, jednak byłoby wygodniej mieć większą kontrolę nad tym procesem.
Dostosuj proces do swoich potrzeb
Na szczęście jest więcej parametrów, których możemy użyć. Przyjrzyjmy się niektórym z nich:
--table może służyć do dołączania określonych tabel--use-database-names zachowa oryginalne nazwy baz danych tak bardzo, jak to możliwe. Jednak nieprawidłowe identyfikatory .NET nadal zostaną zmienione--context może służyć do nadania wygenerowanemu kontekstowi DbContext własnej nazwy--context-dir służy do tworzenia szkieletu klasy DbContext w określonym katalogu--output-dir służy do tworzenia klas jednostek w określonym katalogu--force nadpisze istniejącą klasę DbContext i klasy encji
Zmodyfikowałem moje polecenie, aby wyglądało tak:
dotnet ef dbcontext scaffold Name=aspnetcore --table Profiles --table Events
--context AspNetCoreDbContext --context-dir AspNetCoreModels
--output-dir AspNetCoreModels Microsoft.EntityFrameworkCore.SqlServer
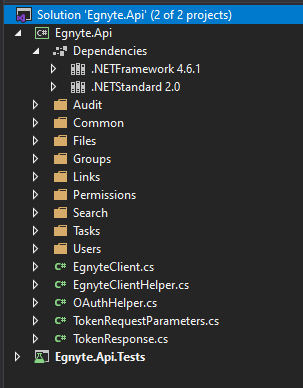
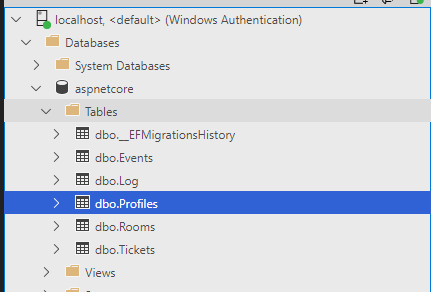
Zobaczmy, jakie klasy zostały wygenerowane.
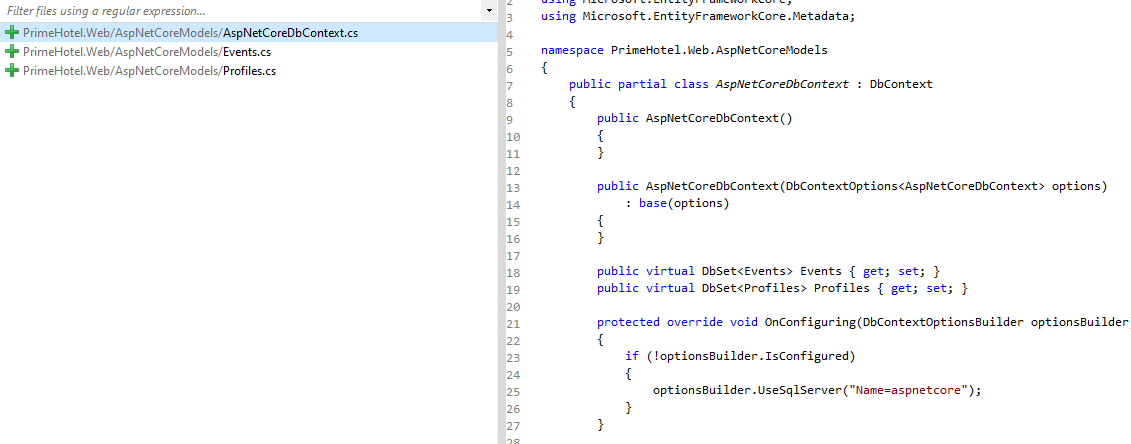
Zwróć uwagę, że zostały wygenerowane tylko tabele Events i Profiles, klasa DbContext ma nazwę AspNetCoreCotext i wszystko zostało wygenerowane w katalogu AspNetCoreModels. O to chodziło!
Ograniczenia
Inżynieria wsteczna wykonuje ogromną pracę polegającą na tworzeniu szkieletów klas encji, więc nie musimy pisać jej samodzielnie. Istnieją jednak pewne ograniczenia tego procesu:
- nie wszystko na temat modelu jest przedstawione w schemacie bazy danych. Na przykład hierarchie dziedziczenia, typy własne i tabele dzielone nie zostaną odtworzone
- ponadto dokumentacja EF Core twierdzi, że istnieją pewne typy kolumn, które nie zostaną uwzględnione w modelu
- typy dopuszczające wartość null nie zostaną zamapowane jako dopuszczające wartość null. Na przykład kolumny typu
string, które mogą mieć wartość null, nie będą mapowane jako typ string?. Taką zmianę trzeba dodać samodzielnie.
Więcej o tym możesz przeczytać w tym artykule Microsoft-u.
Aktualizowanie modelu
Zawsze, gdy coś się zmieni w bazie danych, będziesz musiał zaktualizować swój model. Większość zmian będzie trywialnych, takich jak dodanie kolumny do tabeli, zmiana nazwy tabeli lub zmiana typu kolumn. Te zmiany można szybko wprowadzić w klasach encji własnoręcznie.
Jeśli jednak nie masz pewności, jak mapować zmiany, zawsze możesz ponownie wygenerować cały DbContext ze wszystkimi klasami encji. Aby to zrobić, użyj parametru --force w poleceniu scaffold. Należy jednak pamiętać, że wszystkie zmiany wprowadzone ręcznie zostaną nadpisane. Obecnie nie ma możliwości aktualizacji modelu ze schematu bazy danych i zachowania ręcznych zmian.
Aktualizowanie bazy danych
Tworzenie szkieletu DbContext to tylko sposób na generowanie klas pasujących do bazy danych. Oznacza to, że możesz dodać migracje nawet do istniejącej bazy danych.
Najpierw musisz dodać AspNetCoreDbContext do kontenera DI. Przejdź do pliku Startup.cs i w metodzie ConfigureServices dodaj następujący wiersz.
services.AddDbContext<AspNetCoreDbContext>(options =>
options.UseSqlServer(Configuration.GetConnectionString("aspnetcore")));
Teraz możesz dodać migracje do drugiej bazy danych. Dobrą praktyką jest rozdzielenie modeli i migracji dla każdej bazy danych. Wykonaj to polecenie:
dotnet ef migrations add InitialCreate --context AspNetCoreDbContext --output-dir Migrations/AspNetCore
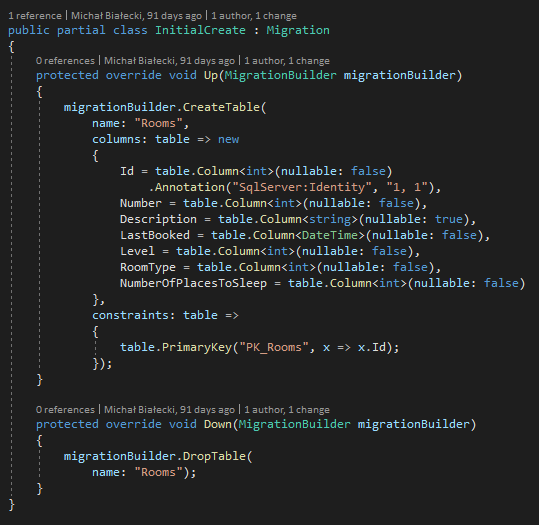
Spójrzmy co zostało wygenerowane:
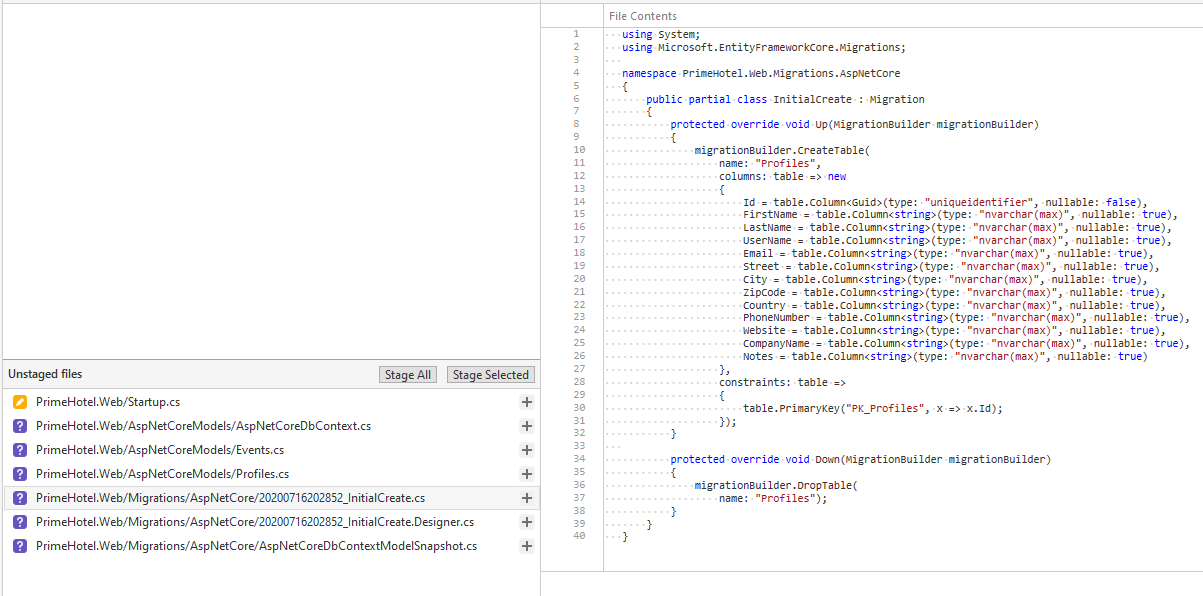
Warto zwrócić uwagę na jedną rzecz. Entity Framework Core wygenerował początkową migrację ze wszystkimi zmianami, które są obecnie w AspNetCoreDbContext. Może być konieczne wyczyszczenie wszystkich zmian w tej migracji, ponieważ te tabele już istnieją.
Podsumowanie
Podczas dodawania Entity Framework Core 5 do istniejącej bazy danych dobrym pomysłem jest stworzenie szkieletu klas jednostek i kontekstu za pomocą dedykowanego narzędzia .NET CLI. Na szczęście istnieje kilka parametrów, które możesz użyć, aby zbudować dokładnie to, czego potrzebujesz i tak jak tego potrzebujesz.
Migracje EF Core 5 można dodać później, aby zapewnić aktualność bazy danych za pomocą kodu. Jedną z rzeczy, o których należy pamiętać, jest to, że ponowne zaktualizowanie DbContext z bazy danych spowoduje nadpisanie wszystkich zmian, które zostały wprowadzone ręcznie. Z tego powodu tworzenie szkieletów DbContext jest raczje operacją jednorazową.
Cały zamieszczony tutaj kod został zademonstrowany na przykładzie projektu PrimeHotel, który jest dostępny na moim GitHubie, więc możesz go bezpłatnie pobrać i na nim eksperymentować. Spójrz również na ten post, jak uruchomić ten projekt: PrimeHotel – jak uruchomić projekt.
Mam nadzieję, że podobał Ci się ten post. Pozdrawiam! 🙂