
From an early development age, I was taught, that duplication is a bad thing. Especially when it comes to storing data. Relational databases were invented to show data that relates to each other and be able to store them efficiently. There are even a few normalization rules, to be able to avoid data redundancy. We are slowly abandoning this approach to non-relational databases because of their simplicity and storage price reduction.
DRY – don’t repeat yourself. Every piece of knowledge must have a single, unambiguous, authoritative representation within a system. (Wikipedia)
The concept of breaking
Let’s look at the example.

In this example, we see a network of stateful services that exchange data about products. Data can came from many sources and we need to send them to many destinations. Data flow from one service to another. Here are a couple of rules:
- every micro-service has data about its own specific thing and keeps it persistent
- services work in a publisher-subscriber model, where every service can publish the data and receive the data it needs
- services don’t know about each other
Does this sounds familiar?
Event-driven microservices
Event-driven programming isn’t a new thing, which we can check in Wikipedia. It is a program, where the flow of the program is triggered by events. It is extensively used in graphical user interfaces and web applications, where user interactions trigger program execution.
Every major platform supports event-driven programming, there is AWS Lambda by Amazon, Azure Functions by Microsoft and Google Cloud Functions by Google. All of those technologies offer event triggering.
In back-end micro-services, an event can be for example a web request or a service bus message. Let’s use Service Bus messages, where every service will be connected to the bus and can act both as a publisher and subscriber.

In this architecture usage of Service Bus is crucial, because it provides some distinctive features:
- services are lously coupled, they don’t know about each other. Building another micro-service that needs specific data is just a matter of subscribing to right publishers
- it’s good for scalability – it doesn’t matter if 1 or 10 instances of services subscribes to a certain topic – it will work without any code change
- it can handle big load – messages will be kept in a queue and service can consume it in its own pace
- it has build-in mechanisms for failure – if message could not be processed, it will be put back to the queue for set amount of times. You can also specify custom retry policy, that can exponentialy extend wait time between retries
If you’d like to know more about Microsoft Service Bus in .Net Core, jump to my blog posts:
What happens when it fails?
When we notice that there might be something fishy going on with or micro-service, we have to be able to fix it. It might miss some data, but how to know exactly what data this micro-service should have? When micro-services are stateful, we have

You can see how a micro-services state can be fixed by a single admin request. Service can get all of the data only because other services are stateful. This came in handy not always in crisis situations, but also when debugging. Investigating stateless services when you actually don’t know what data came in and what came out can be really painful.
But it’s data duplication!

That’s right! In the mentioned scenario each micro-service is stateful and have its own database. Apart from all the good things I mention I just need to add, that those services are small and easy to maintain. However, they could be merged into one bigger micro-service, but that wouldn’t micro service anymore, would it? Also when services have less to do, they also work faster.
Ok, but back to the problem. It’s data duplication! With a big D! Almost all services share some parts of the same thing, how do we know which one is correct and which one to use? The answer is simple: keep data everywhere, but use only one source.
Single source of truth – it is one source for getting certain data. Whenever you want some data that are consistent and up-to-date, you need to take it from the source of truth. It guarantees that when two clients request the data at the same time, they will get the same result. This is very important in a distributed system, where one client can feed data on a product page showing titles and prices and another one should show the same data in a cart or checkout.
In our
An inspiration
Some time ago I got inspired by Mastering Chaos – A Netflix Guide to Microservices by Josh Evans talking about Netflix micro-services architecture. I strongly encourage you to watch it.
Below you can see how micro-services talk to each other and process data.
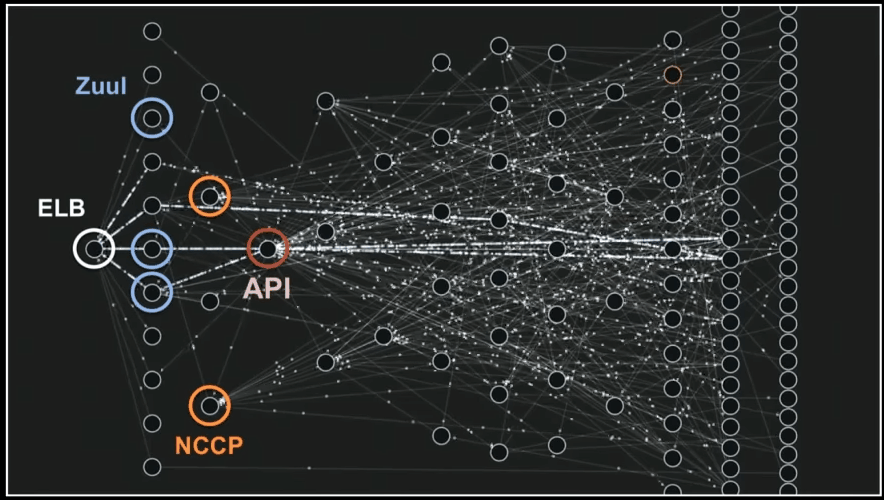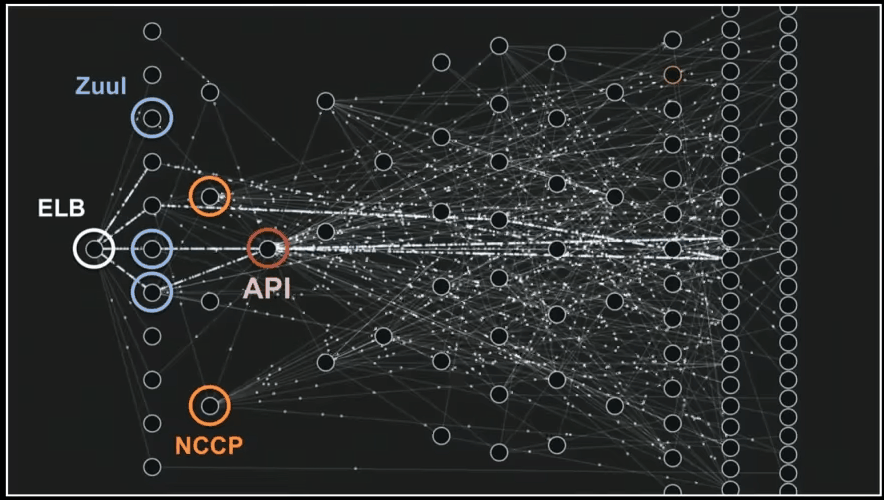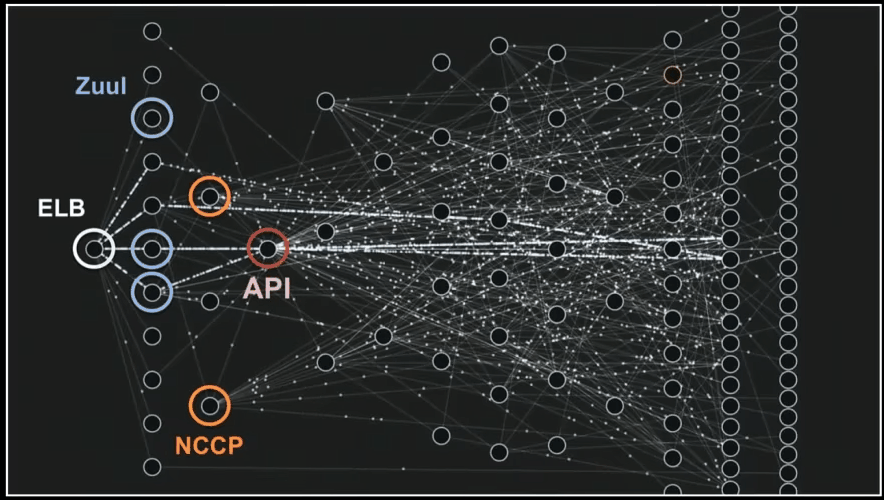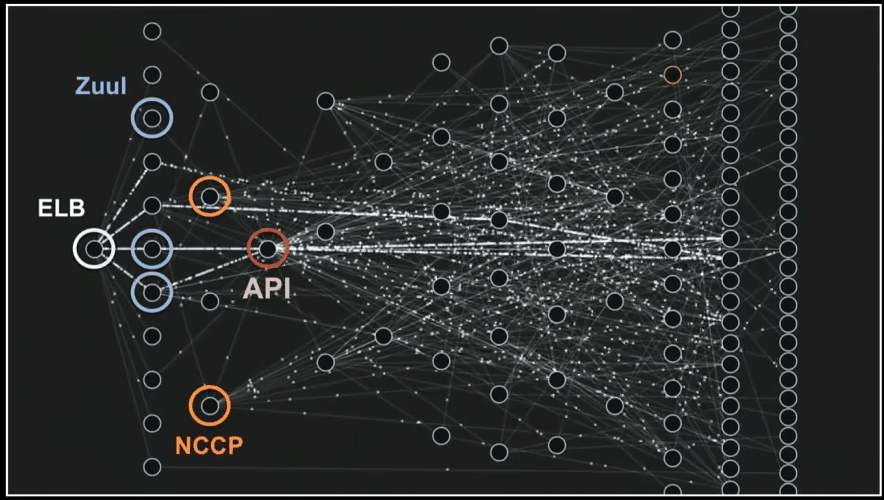
Yes, it’s a cool gif from mentioned presentation that I really wanted to show you 🙂
service should not communicate each other, should use a bus event
No, the bus event is used to publish an event. The subscriber services will communicate with the related service to update their data.
For example, Customer Service publish a CustomerUpdated event with its ID. Order Service which has subscribe the service will use that ID to exchange the whole information of updated Customer and update their own copy of data if needed(Maybe order service only store customer name and updated information is not name, then Order Service no need to do anything).
Theres multiple patterns.. Unfortunately your reply isnt entirely correct if you want to reduce coupling. By only passing ID’s around two services still need to be aware of the public API in order to work. The alternative is “Event Carried State Transfer” which means you publish the entire change to the bus and the subscriber listens and pulls out the data it cares about