Azure CosmosDB table API is a key-value storage hosted in the cloud. It’s a part of Azure Cosmos DB, that is Microsoft’s multi-model database. It’s a globally distributed, low latency, high throughput solution with client SDKs available for .NET, Java, Python, and Node.js.
Interesting thing is that Microsoft guarantees that for a typical 1KB item read will take under 10ms and indexed writes under 15ms, where’s median is under 5ms with 99.99% availability SLA.
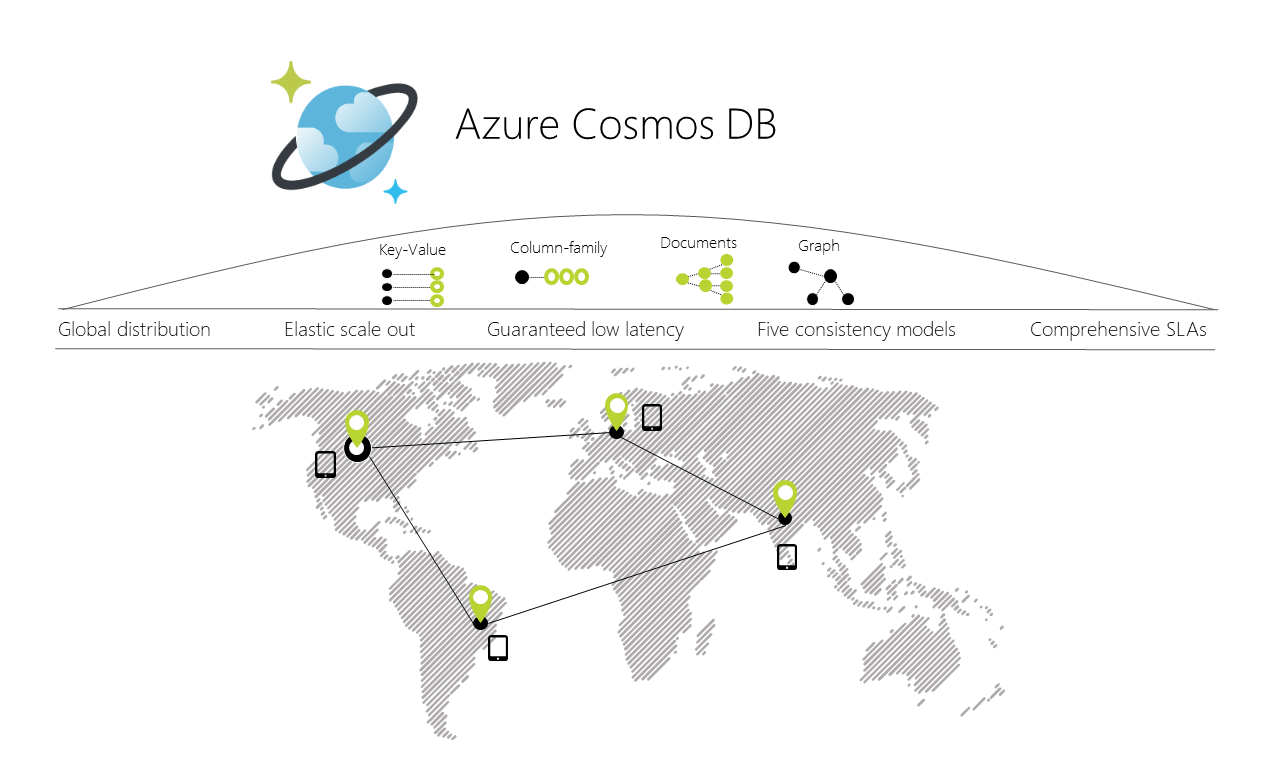
Image from https://docs.microsoft.com/en-us/azure/cosmos-db/media/introduction/
Why NoSQL?
First of all, if you’re not that familiar with the differences between relational and non-relational databases, go have a look at my short article about it: https://www.michalbialecki.com/2018/03/16/relational-vs-non-relational-databases/
NoSQL databases are databases where data are kept without taking care of relations, consistency, and transactions. The most important thing here is scalability and performance. They gained it’s popularity thanks to Web 2.0 companies like Facebook, Google, and Amazon.
Different data organization – data can be kept is a few different forms, like key-value pairs, columns, documents or graphs.
No data consistency – there are no triggers, foreign keys, relations to guard data consistency, an application needs to be prepared for that.
Horizontal scaling – easily scaling by adding more machines, not by adding more power to an existing machine.
What is a key-value database

It is a data storage designed for storing simple key-value pairs, where a key is a unique identifier, that has a value assigned to it. Is it a storage similar in concept to dictionary or hashmap. On the contrary from relational databases, key-value databases don’t have predefined structure and every row can have a different collection of fields.
Using CosmosDB Table API
To start using CosmosDB Table API go to Azure Portal and create a CosmosDB account for table storage. Create a table – in my example it’s name is accounts. Then you need to copy the primary connection string – this is all you need.
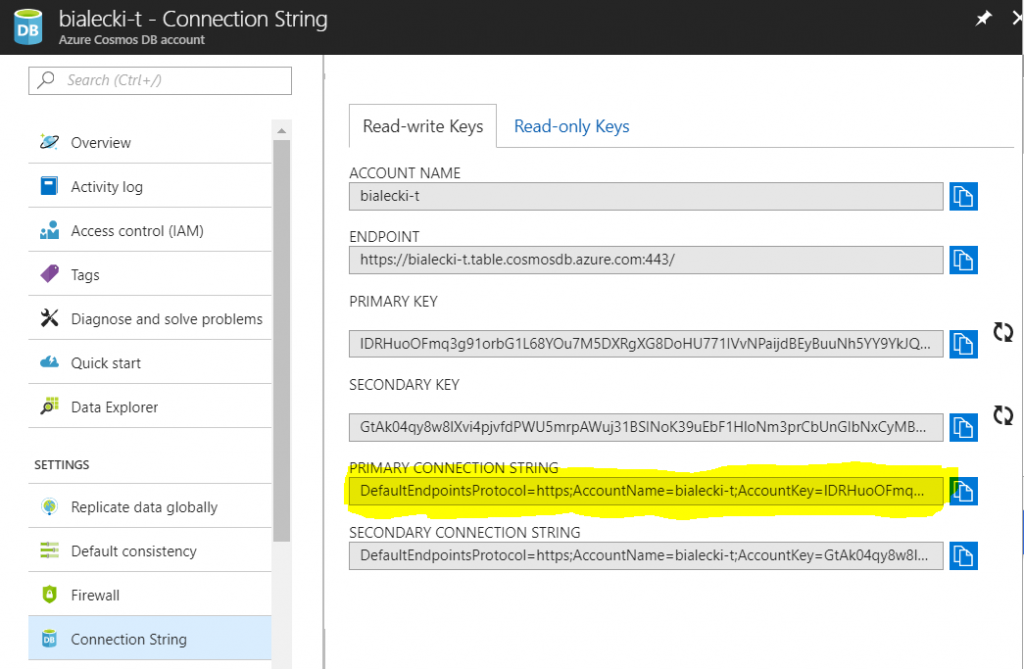
Now let’s have a look at the simple retrieve operation.
// Create a retrieve operation that takes a customer entity.
TableOperation retrieveOperation = TableOperation.Retrieve<CustomerEntity>("Smith", "Ben");
// Execute the retrieve operation.
TableResult retrievedResult = table.Execute(retrieveOperation);
Notice, that in order to get an entity you needed to provide two keys: Smith and Ben. This is because every table entity have a PartitionKey and RowKey property. RowKey is unique among one PartitionKey and the combination of both is unique per table. This gives you a great opportunity to partition data inside of one table, without a need to build your own thing.
Before starting coding install: Microsoft.Azure.CosmosDB.Table, Microsoft.Azure.DozumentDB and Microsoft.Azure.KeyValue.Core. The last one is Microsoft.Azure.Storage.Common that I installed with v8.6.0-preview version(you need to check include prerelease in nuget package manager to see it). It might work with the newer one, but it is not available when I write this text.
You can create a table client in such a way:
var storageAccount = CloudStorageAccount.Parse(CosmosBDConnectionString);
var tableClient = storageAccount.CreateCloudTableClient();
var accountsTable = tableClient.GetTableReference("accounts");
An entity that I use for my accounts table looks like this:
using Microsoft.Azure.CosmosDB.Table;
namespace MichalBialecki.com.ServiceBus.Examples
{
public class AccountEntity : TableEntity
{
public AccountEntity() { }
public AccountEntity(string partition, string accountNumber)
{
PartitionKey = partition;
RowKey = accountNumber;
}
public double Balance { get; set; }
}
}
Notice that there is a constructor with PartitionKey and RowKey as parameters – it has to be there in order for entity class to work.
In an example that I wrote, I need to update account balance by the amount I’m given. In order to do that, I need to retrieve an entity and update it if it exists or add it if it doesn’t. The code might look like this:
private static readonly object _lock = new object();
public double UpdateAccount(int accountNumber, double amount)
{
lock(_lock)
{
return UpdateAccountThreadSafe(accountNumber, amount);
}
}
private double UpdateAccountThreadSafe(int accountNumber, double amount)
{
var getOperation = TableOperation.Retrieve<AccountEntity>(PartitionKey, accountNumber.ToString());
var result = accountsTable.Execute(getOperation);
if (result.Result != null)
{
var account = result.Result as AccountEntity;
account.Balance += amount;
var replaceOperation = TableOperation.Replace(account);
accountsTable.Execute(replaceOperation);
return account.Balance;
}
else
{
var account = new AccountEntity
{
PartitionKey = PartitionKey,
RowKey = accountNumber.ToString(),
Balance = amount
};
accountsTable.Execute(TableOperation.Insert(account));
return amount;
}
}
I used a locking mechanism so that I’m sure that this operation is atomic. It is because I made this class as a singleton that I want to use in parallel while processing service bus messages.
After reading bunch of messages, my table looks like this. Also Balance is saved there without a need to define it in any schema.
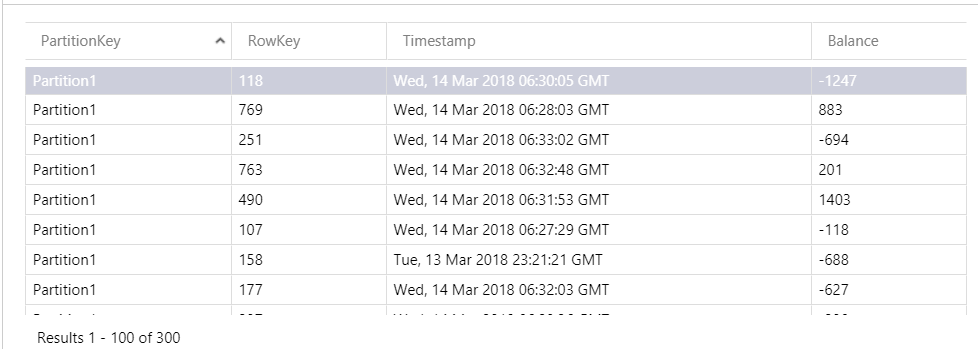
If you’re interested in more simple examples, you can find it at this Microsoft page: https://docs.microsoft.com/en-us/azure/cosmos-db/tutorial-develop-table-dotnet.
If you’re interested in CosmosDB document storage, go to my article about it: https://www.michalbialecki.com/2017/12/30/getting-started-with-cosmosdb-in-azure-with-net-core/


 Actor model is best suited for data that is well grained, so that actors can be easily identified and their state can be easily decoupled. Accessing data by an actor is instant, because it holds it in memory and the same goes to notifying other actors. Taking that into account, Microsoft Orleans will be most beneficial where application needs to handle many small operations that changes application state. In a traditional storage, in example SQL database, application needs to handle concurrency when accessing the data, where in Orleans data are well divided. You may think that there have to be data updates that changes shared storage, but that’s a matter of changing the way the architecture is planned.
Actor model is best suited for data that is well grained, so that actors can be easily identified and their state can be easily decoupled. Accessing data by an actor is instant, because it holds it in memory and the same goes to notifying other actors. Taking that into account, Microsoft Orleans will be most beneficial where application needs to handle many small operations that changes application state. In a traditional storage, in example SQL database, application needs to handle concurrency when accessing the data, where in Orleans data are well divided. You may think that there have to be data updates that changes shared storage, but that’s a matter of changing the way the architecture is planned.